








数据库市场形成今天的格局已经很久了,商业数据库为王,这几乎没有变过。不过,云来了,以AWS、阿里云为代表的云服务商携云原生数据库发起了新一轮挑战。与以往历次的挑战不同,这次的竞赛换了赛道。
3月21日,阿里云对外发布了POLARDB v2.0。此前的POLARDB针对的是MySQL用户,这一次POLARDB还可以兼容Oracle数据库。据悉,这也是首个兼容 Oracle的云原生数据库,可帮助金融、医疗、制造等大型企业在数小时内完成业务迁移,10TB数据备份只需10分钟。
因云而生的POLARDB
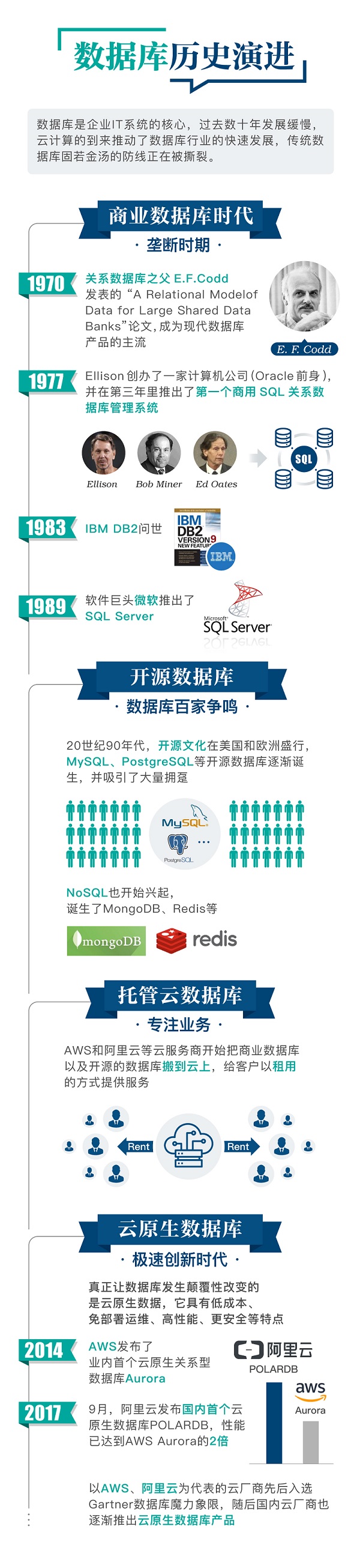
数据库诞生于上个世纪70年代,经过这些年的发展,无论是技术还是市场格局都已经趋于稳定,因此市场很长时间以来一直处于波澜不惊的状态,不过,云时代的到来打破了这种平静,因为在云时代传统数据库面临很多新的挑战,这就给了新生的云原生数据库以机会。
在2019阿里云峰会·北京站上,阿里云智能总裁张建锋在演讲时曾提到了云给这个世界带来的三个变化,即IT基础设施的云化、核心技术的互联网化、应用的数据化和智能化。
“基础设施的云化需要一套新的系统,需要基于互联网技术来进行改造。因此,下一代的技术一定构建在互联网技术和云化基础设施上的。”张建锋表示。
而阿里云的数据库POLARDB正是适应基础设施的云化而诞生的,正因为此,POLARDB这类数据库也被称为云原生数据库,包括AWS的Aurora也是这一类型的代表。
实际上,阿里云早期也是传统数据库的使用者,正是因为云的诞生,因为自身业务不断成长,发现传统数据库越来越难以满足自身的需求,才有了自研的云原生POLARDB。
“阿里的业务很复杂,数据量很大,随着业务的发展,基于开源数据库的分布分表中间件的解决方案已经不能满足。这就是POLARDB诞生的直接原因。”阿里云智能数据库产品线总负责人李飞飞说。


阿里云智能数据库产品线总负责人李飞飞
享受云等诸多技术红利
作为一款诞生于云时代、一开始就架构在云平台之上的云原生数据库天生地具有很多优势。比如,弹性伸缩能力就是云原生数据库最重要的特点,即当用户业务量低的时候,就少分配资源;当业务负载高的时候,通过只读节点等逐渐扩展的方式,让数据库支持业务的增长。这种弹性伸缩的能力还带来另一个好处,就是按需付费,成本节约。所以,云原生数据库往往具有更高的性价比。
“传统数据库的典型架构就是单节点架构,有存储引擎、查询引擎和优化器引擎,再上面是SQL Parser,这一套架构中存储和计算是绑定在一起的,而云原生数据库存储与计算是分离的。”李飞飞表示。
李飞飞介绍说,POLARDB采用的是分布式共享存储架构,计算与存储分离。由于计算与存储的解耦,存储就可以通过RDMA高速网络做成一个分布式存储,而看起来仍然像一个本地盘。正是由于采用了计算与存储分离的架构设计使得POLARDB的大数据容量可以达到100TB,这是开源数据库难以企及的,也成为POLARDB很多早期用户采用它来取代MySQL的一个主要原因。
除了借助RDMA等网络技术实现弹性伸缩能力之外,POLARDB还享受了很多现代技术的红利。比如,POLARDB采用了英特尔的傲腾——这是一种访问速度介于内存和SSD之间的新型存储介质,如果需要扩容,可以在5分钟之内完成节点规格的升级和进行只读节点的扩展,极速适配。
实际上,傲腾的对数据库的影响不只是快速,它也在一定程度上改变了数据库的设计逻辑,让数据一旦写了之后实时就可持续性了,持久化了。
另外,像GPU加速在POLARDB中也有采用。在POLARDB中一些重复性或相似性比较高的计算,会Offload到FPGA来做,通过FPGA的定制化的计算模块重复调用,来节省CPU的时间,从而带给用户更好地体验。
不断升级的产品
POLARDB也在不断升级,目前阿里云还在研发POLARDB的分布式版本,今年会宣布公测。该版本的目标客户是业务数据量超过单机数据库的承受能力,业务复杂对资源弹性要求高,例如要求数据不丢失,系统高稳定高可用。
据悉,它能支持更海量的数据、更高并发的处理能力,基于阿里的核心业务十余年打磨,围绕高效低成本存储引擎X-Engine,提供企业化高可用的X-Paxos协议实现。
李飞飞介绍,POLARDB分布式版本的一大特性就是解决了分库分表问题。早期互联网公司采用基于中间件技术的分库分表技术解决资源扩展问题,但这会大大增加系统的复杂度和对应用的侵入。因为很多时候这意味着业务逻辑的重构、软件的改写,成本非常高。而POLARDB分布式版本具有类似Google Spanner的先进架构,同时又摆脱其昂贵复杂的原子钟依赖。
“阿里很多大促活动,比如‘双11’,光靠云原生共享存储是无法完全解决这个问题。过去两年,我们一直在研发自己的分布式存储技术,它的核心思路就是分布分表,但我们不希望用中间件的解决方案。”李飞飞说。
李飞飞解释说,与基于中间件技术的分库分表不同,阿里云希望做一个原生的分布式数据库,在内核里面做分布分表,以尽可能减少对业务层的冲击。现在阿里云要把分布式数据库的技术和POLARDB有机地结合起来。
“我们的目标是打造一个通用的商业数据库,要求非常产品化、标准化,能够支持不同产品。未来POLARDB分布式版本能够提供一个基于共享存储的一写多读的云原生数据库,同时利用分布式架构能够快速灵活拓展。这样,不管是在公有云上,还是针对线下的一些企业级超大规模的用户,我们都能够用POLARDB去统一满足用户需求。”李飞飞说。
有挑战更是机遇
很显然,在数据库市场,POLARDB是一个新来者,甚至与AWS的Aurora相比,POLARDB也要晚几年。但李飞飞认为,作为挑战阿里云的数据库具有自己的独特优势,而大的优势是背后有阿里的业务在推动。
“任何技术都是业务推动来衍生的,只要你有业务场景,技术就一定会逐步从发展到领先。比如阿里电商‘双11’在世界上就绝无仅有,阿里云的数据库必须经受住海量和高并发的实战考验。”李飞飞说。
实际上,阿里云数据库技术也得到国际咨询机构的认可,在2018 Gartner数据库魔力象限中,阿里云成为国内首个入选的科技公司。
“这代表了阿里云的数据库技术已经和顶级数据库厂商站在了同一个舞台。中国数据库厂商有这个机会,非常荣幸。不能只说是阿里的功劳,也是整个中国IT产业、中国经济发展的结果。如果没有中国数字化经济的蓬勃发展,我们是不可能取得这样的成功。”李飞飞说。
李飞飞坦言,作为挑战者阿里云数据库要真正与数据库巨头竞争,面临不小的挑战。
第一个是阿里云和传统数据库厂商有一个非常大的不同,就是传统数据库厂商可以只研发数据库产品,而阿里云数据库还要支持集团的业务,还要服务自己云上的客户以及私有云、混合云的外部客户。
“我们面临的是非常复杂的一个场景:又要研发,又要运维。既要支持集团的业务,又要支持云上的业务,所以稳定性、安全运维这绝对是我们第一生命线。”李飞飞表示。
第二个挑战也是李飞飞认为最核心的挑战,是混合云部署所带来的,这里面既有技术上的挑战也有业务上的挑战。比如,你怎么保证安全、稳定、高效地部署混合云,混合云的数据架构如何设计等等。
第三个是数据的安全隐私保护,这是阿里云数据库一直不敢放松的。
第四点就是智能化大规模落地和应用。当系统越来越复杂,数据量越来越大,运维挑战越来越高的时候,就必须利用人工智能、机器学习的技术尽可能地实现自动运维,提高运维效能。
“这些是挑战也是机遇,阿里云的业务快速发展正在不断驱动我们技术的发展,验证和带领技术不断往前走,我们已经走在了云原生数据库领域的前列。”李飞飞总结说。
相关阅读:























