








流计算的前世今生
在大数据时代的初期,我们面临的数据主要是大容量的静态数据集,针对离线和大规模数据分析设计的Hadoop依靠HDFS和Mapreduce可以灵活、高效的处理这种数据形态。然而,随着大数据时代的演进,具有实时持续到达、到达次序独立且高度无序等特征的流式数据在当前商业环境中变得越来越常见,人们迫切的想对这种流式数据进行实时分析并进而转化成商业价值,于是推动了大数据技术的演进。
在大数据技术从批处理走向流处理的过程中,主要产生了storm、spark streaming、Flink等成熟的框架。Storm是仅支持流处理的框架,其核心概念是将Spouts和Bolts连接在一起形成拓扑结构(Topology),然后将用户提交的应用程序逻辑在Topology中指定。
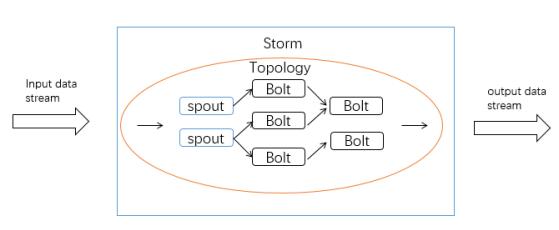
然而,传统的Storm(非Trident)只能提供at least once语义,而如果通过Trident 实现了exactly once语义,则会以牺牲时延为代价,因此storm的两种方案都是局部最优,而非全局最优。
Spark Streaming是针对批量数据处理设计的混合框架,其流处理功能是通过将流处理作业分解为一系列微批处理作业来实现的,而负责进行处理的引擎其实还是Spark。
Spark Streaming相比于Storm能提供更稳定的exactly once语义,但由于其核心概念是微批处理,因此其优势在于高吞吐量而非时延,其时延与Storm、Flink相比较高。
Flink是针对流式数据处理设计的混合框架,可以通过把批量数据看成有界的流式数据来实现批处理,其核心概念是将Flink上运行的程序映射为streaming dataflows,应用程序逻辑通过streaming dataflow内的多个transformation operator实现。
由于Flink对流式数据处理的针对性设计,只需要很少配置就能实现高吞吐与低延迟。Flink支持exactly once语义,并且其checkpoint机制保证了即使在发生故障的情况下也能保障exactly once语义。
云上的流计算服务SCS:从零件到服务
在当今瞬息万变的商业赛道上,早一步出发便意味着可以更早接触到商业机会、更早占据市场份额,进而野蛮生长。然而如果选择基于开源框架的“零件”形态的流计算,便意味着无论是基础设施建设还是日常运维,亦或是安全保障,这些与成本和风险息息相关的模块都需要自己来维护,从而分散了聚焦于业务的精力,又何谈把握转瞬即逝的商业机会?
于是,与商业场景的低适配推动着流计算走向了云端。为了让用户可以以低成本获取到无尽的流计算分析能力,云厂商将云端近乎无限的计算、存储、技术等资源整合,把流计算在云端以服务的形式进行技术革新,形成了云上的流计算服务。
腾讯云流计算SCS是腾讯基于在社交、视频、游戏等海量业务场景积累的经验,为了帮助云端用户达成降本增效的目的,通过深度整合深耕互联网科技领域近20年积累的基础设施,以PaaS服务的形式提供的云端流计算服务。
腾讯云流计算SCS服务将提供:
流计算SCS助力工业智能制造
SCS将从五个智能化发力,全面助力工业智能制造:
基于SCS实时进行数据分析,实现产品实时定位、产品实时管理,助力产品智能化。
基于SCS跟踪生产线进度,实时监控生产线压力,实现智能调度,助力生产智能化。
基于SCS实现预防性维护,从而避免高成本的设备故障风险,助力装备智能化。
基于SCS实时过滤无效信息,准确识别用户需求,进行自动化个性定制产品生产,助力服务智能化。
基于SCS通过设备IOT组件采集信息并进行多维度、多指标实时分析,助力管理智能化。
从传统制造到智能制造转型的进程中,SCS将火力全开。
流计算的未来
虽然流计算与IOT相关场景契合度极高,但流计算在互联网、电商、金融等行业同样拥有着广阔的应用场景如点击流分析、金融风控、实时推荐等。
未来的流计算,将与AI深度结合,从流计算走向流AI,成为人工智能时代的基础设施。流计算将流淌在整个社会的每一个角落,并不断为我们带来富有价值的洞见!





















