








8月21日,腾讯云正式对外宣布成功创造了128卡训练ImageNet业界新记录,以2分31秒的成绩一举刷新了这个领域的世界记录。若改变跨机网络带宽,该成绩还可以进一步提升至2分2秒,将这一记录提升到一个全新的高度。
这次记录是基于公有云25Gbps的VPC网络环境,使用128块V100 GPU,借助最新研制的Light大规模分布式多机多卡训练框架创造的,最终成绩定格在2分31秒训练 ImageNet 28个epoch,TOP5精度达到93%,之前的业界好成绩是2分38秒。据了解,这项记录的背后团队来自腾讯云智能钛团队、腾讯机智团队、腾讯优图实验室以及香港浸会大学计算机科学系褚晓文教授团队。
作为人工智能最重要的基础技术之一,深度学习的应用已经快速延伸到智慧城市、智能制造等众多场景。然而与需求同步衍生的是在深度学习训练中产生的诸多问题,比如数据量庞大且训练耗时长、计算模型/结构愈渐复杂、参数量大、超参数范围广泛等。这些问题已经阻碍了深度学习开发应用的进度。如何做高性能AI训练和计算,不仅关乎到AI生产研发效率,还对AI产品的迭代效率和成功上线产生重要影响,而高效训练的一个非常重要的基准是如何在更短时间内对大型可视化数据库ImageNet做一次训练。
正是在这样的背景下,腾讯云联合多个团队研发出了Light大规模分布式多机多卡训练框架,从深度学习训练的速度、多机多卡的扩展性、batch收敛等方面,为业界提供了一套全新的训练解决方案。
在单机训练速度方面,腾讯云首先利用GPU云服务器的内存和SSD云盘,在训练过程中为训练程序提供数据预取和缓存,加速了访问远程存储数据。而针对大量线程相互抢占导致CPU运行效率低下问题,腾讯云通过自动调整最优数据预处理线程数来降低CPU的切换负担,让数据预处理和GPU计算并行,提升了整体训练的速度。
在多机扩展训练方面,以往的TCP环境下,跨机通信的数据需要从显存拷到主存,再通过CPU去收发数据,计算时间短加上通信时间长,使多机多卡的扩展性受到了很大挑战。腾讯云则凭借Light高效扩展了多机训练,通过自适应梯度融合技术、层级通信+多流手段、层级topk压缩通信算法等,充分利用通信时的网络带宽,优化了跨机通信的时间。
此外,为充分利用大规模集群算力,目前业界主要通过不断提升训练的batch size来提升训练速度,但是batch size的增大会对精度带来影响和损失。为解决这一问题,腾讯云通过大batch调参策略、梯度压缩精度补偿、AutoML调参等方法,有效实现了在增大batch size的同时,最小化其对精度的影响。
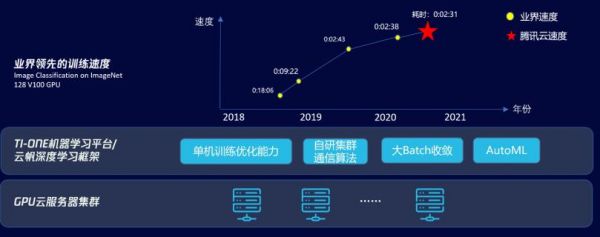
通过 Light大规模分布式多机多卡训练框架及平台等一系列完整的解决方案,ImageNet的训练结果取得了新突破。并且在取得高效训练的同时,也将其能力集成到腾讯云智能钛机器学习平台,并广泛应用在腾讯内外部的业务。
接下来,联合项目团队还将进一步提升机器学习平台易用性,训练和推理性能,构建稳定、易用、好用、高效的平台和服务,为算法工程师提供有力的机器学习工具,助力各行各业用户业务的发展。























