








不受过良好训练的人工智能(AI)系统可以加强偏见,因此AI系统必须得到公平的培训。专家说,AI公平性是每个特定机器学习模型的数据集问题。人工智能公平是一项新认识的挑战。大型云提供商正在开发和宣布有助于解决AI公平性的工具。
Facebook宣布内部软件工具开发,以便在2018年5月搜索训练数据集中的偏见。从那时起,Amazon,Microsoft、,Google以及最近IBM宣布了开源工具,用于检查训练模型中的偏差和公平性。
以下是这些工具的设计目标,彼此之间的立场,以及为什么IBM的信任和透明度公告很重要。

AI公平挑战
AI的核心挑战是深度学习模型是“黑盒子”。对于仅仅是人类来说,理解各个训练数据点如何影响每个输出分类(推理)决策是非常困难的-并且通常根本不可能。术语“不透明”也用于描述这种隐藏的分类行为。当您无法理解系统如何做出决策时,很难相信系统。
在机器学习开发者社区中,与opaque相反的是“透明”。透明的深度学习模型将以可理解的方式揭示其分类过程,但是创建透明模型的研究仍处于早期阶段。
2018年1月,一大批中国组织参与了人工智能标准化白皮书。白皮书承认人工智能中的道德问题,尚未提供补救措施,并说:
“我们也应该警惕人工智能系统制定有道德偏见的决策。例如,如果大学使用机器学习算法来评估录取,并且用于训练的历史录取数据(有意或无意)反映了先前录取程序(例如性别歧视)的一些偏见,那么机器学习可能会在重复计算期间加剧这些偏差。,造成恶性循环。如果不加以纠正,就会以这种方式在社会中存在偏见。“
白皮书的贡献者包括:阿里云(阿里云),百度,中国电信,华为,IBM(中国),英特尔(中国),腾讯等等。我相信这些组织也在努力解决培训AI系统中的偏见和歧视问题,但尚未公开宣布工具。
人工智能的公平状态
Facebook在其2018年5月的公告中仅通过名称确定了其中一个内部反偏见软件工具。“公平流程”衡量模型如何与特定人群互动。Facebook的团队与几所学校和研究所合作开发其工具。Facebook尚未公开发布其Fairness Flow工具。
亚马逊
AWS于2018年7月发布了一篇博客,该博客在准确性,误报率和误报率方面构建了机器学习公平性。但AWS还没有发布开发人员工具来评估模型培训其他方面的公平性。
微软
Microsoft Research于2018年7月发表了一篇论文,描述了二进制分类系统的公平算法,以及实现该算法的开源Python库。微软的工作包括预处理培训数据和后处理模型输出预测。但是,它不是作为高级开发人员工具实现的;它适用于熟悉深度学习代码的Python开发人员。
谷歌
2018年9月,Google的People+AI Research(PAIR)计划比仅提供开发人员库更进一步,宣布其“假设工具”。假设分析使开发人员能够在视觉上分析输入数据集和训练的TensorFlow模型并包含公平性评估。谷歌的假设分析工具现在是其开源TensorBoard Web应用程序的一部分。
IBM
在谷歌的假设公告发布一周后,IBM通过宣布可与任何机器学习模式配合使用的可视化开发人员工具,使谷歌获得了一席之地。IBM的品牌AI OpenScale工具使开发人员能够使用任何集成开发环境(IDE)分析任何机器学习模型。IBM还开放了其机器学习公平工具作为AI Fairness 360工具包。IBM使用Kubernetes编排将其机器学习工具链集装箱化,并可在任何公共云中运行(不出所料,其IBM OpenScale教程在IBM Cloud上的Watson Studio中运行)。
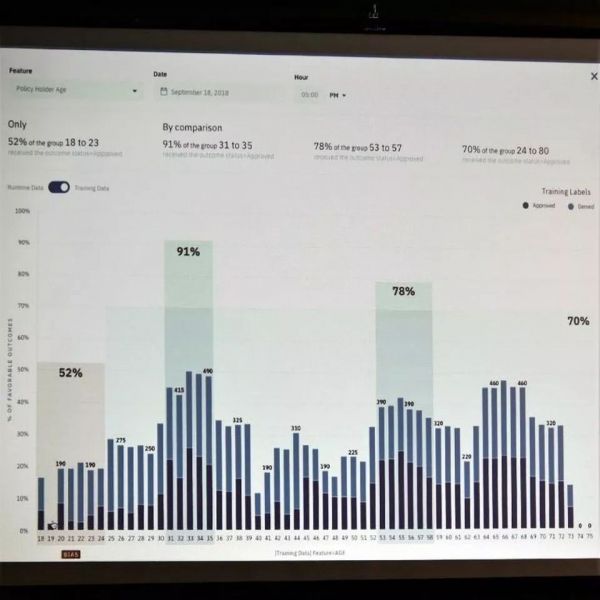
人工智能公平的透明度和开源
最终,在训练有素的机器学习模型中解决偏差的最佳答案将是构建透明模型。但是因为我们还不知道如何做到这一点,今天的深度学习模型就是黑盒子。因此,偏差和公平性评估工具必须检查每个模型的输入数据集和输出推断结果。我相信更多工具将遵循这条道路。
目前,IBM的开源AI公平工具包通过在任何公共云上使用任何模型类型树立了一个很好的例子。
相关阅读























