现有平台面临的挑战
不同企业开始往容器方向发展的初衷是不一样的,有些企业是因为没有运维工程师或运维团队,而想要借助某个平台实现运维自动化。
有些企业可能是由于计算资源的利用率比较低。虽然一些大型的互联网公司都是动辄拥有成千上万台服务器,但实际上以我个人的经历来看计算资源的利用率都不高,这里有很多历史的原因,其中之一就是为了获得更好的隔离性,而实现隔离好的办法就是采用从物理机到基于虚拟的私有云技术。
对于有着比较长历史的公司,应用部署往往会和本地的运行环境强相关,使得迁移变得非常困难,这时也需要有一个好的解决方案来解耦。另外业务总量的繁多,也会带来管理的复杂度的提高。
为什么选择Kubernetes
上面提到的这些问题在我们的生产实践中都有不同程度的遇到,虽然有很多的解决方案,但是我们最终还是选择了Kubernetes。
Kubernetes首要解决了计算资源利用率低下的问题,得益于此我们的服务器数量减少了一半。容器化解决了计算资源利用率问题。
业务容器镜像一次构建,就能够运行在多种环境上,这种方式减少了对运行环境的以来,给运维平台带来了足够的灵活性,解决了服务商锁定的问题,我们当时考虑的是如果某个IDC服务商不满足服务要求如何做到快速迁移,一般来说大批量的服务迁移代价非常高,需要很长时间,容器化之后业务迁移时间只需要30分钟左右。
通过Kubernetes的架构设计思想我们还可以规范网站系统的架构设计。最后还有一点就是它实现了运维自动化。
向容器云平台迁移前的准备工作
要想向容器云迁移,企业内部需要一定的运维能力,如果企业的规模还不够大,也可以考虑一些国内的容器云服务提供商。下面来说下我们自己所做的一些准备工作。
首先自然是搭建Kubernetes集群,私有Docker镜像仓库构建采用的是harbor,然后是独立出来的集群监控,CI/CD基础设置使用的是Jenkins和helm,分布式存储解决方案用的是Glusterfs。
业务迁移中使用的规范
从2015年底1.0版到之后的1.2、1.3版Kubernetes中的问题还是比较多的,企业要使用它是需要一定勇气的。但现在基本上趋于成熟,对于大部分应用不用太多的改造也可以跑的很好。
即使是这样,也不是所有的应用都可以迁移到容器云中,如果应用能够很好的符合云原生的设计原则当然可以迁移进来,但是大部分的应用并不是按照这样的设计原则设计的。这个时候好的办法是先将业务迁移进来,然后再逐步演进成微服务架构。
在这个过程中我们刚开始其实也没有任何规范,之后才陆续制定了相关规范,下面来具体看下迁移规范。
容器镜像封装的基本原则
早期很多系统架构师都将Docker当做轻量级的虚拟机在使用,但这并不是最佳实践,要想正确的使用Docker需要符合以下基本原则:
- 尽可能设计成无状态服务,它带来的好处就是能够非常容易的做水平扩展
- 尽可能消除不必要的运行环境依赖,如果容器内业务依赖太多水平扩展就会变的非常困难,在传统的部署形式下,无论是虚拟机部署还是物理机部署都经常会产生各种各样没必要的依赖,对于有一定历史的企业这个问题就会非常严重
- 需要持久化的数据写入到分布式存储卷
- 尽可能保证业务单一性,这样能够让分布式应用很容易扩展,同样它也是微服务架构中的设计原则
- 控制输出到stdout和stderr的日志写入量
- 配置与容器镜像内容分离
- 容器中使用K8S内部dns代替ip地址配置形式
- 日志采用集中化处理方案(EFk)
- 采用独立的容器处理定时任务
NameSpace的使用
由于考虑到测试环境和staging等运行环境的资源利用率并不高,所以就想在一个集群内部同时运行开发、测试、staging、生产环境。通过NameSpace实现不同运行环境的隔离,同时应用软件在不同的运行环境之间也不会产生命名冲突。
Service的命名规范
在v1.5版之前Service的命名不能超过24个字符,v1.5版之后最多63个字符。另外还需要满足正则regex[a-z]([-a-z0-9]*[a-z0-9])?的要求,这意味着首字母必须是a-z的字母,末字母不能是-,其他部分可以是字母数字和-符号。一般来说命名方式都是使用“业务名-应用服务器类型-其他标识”的形式,如book-tomcat-n1、book-mysql-m1等。
应用健康检查规范
应用健康检查规范是实现自动化运维的重要组成部分,也是系统故障自动发现和自我恢复的重要手段。目前有两种健康检查方式,分别是进程级和业务级。
进程级健康检查是Kubernetes本身具备的,它用来检验容器进程是否存活,是默认开启的。
业务级的健康检查由我们自己实现,它有三点要求,一是必须要检查自身核心业务是否正常,二是健康检查程序执行时间要小于健康检查周期,三是健康检查程序消耗资源要合理控制,避免出现服务抖动。
健康检查程序在不同环境下有着不同的实现:
web服务下采用HTTPGET方式进行健康检查,需要实现一个“/healthz”URL,这个URL对应的程序需要检查所有核心服务是否正常,健康检查程序还应该在异常情况下输出每一个检查项的状态明细。
其他网络服务下可以采用探查容器指定端口状态来判断容器健康状态。
非网络服务下需要在容器内部执行特定命令,根据退出码判断容器健康状态。
Yaml中Image tag配置规范
部署容器镜像时应该避免使用latest tag形式,否则一旦出现问题就难以跟踪到当前运行的Image版本,也难以进行回滚操作。所以建议每个容器Image的tag应该用版本号来标识。
使用ConfigMap实现应用平滑迁移
早期的1.0版本配置信息都是写在配置文件中的,要做迁移就需要改很多东西,当时就只有几种方法可以传递配置信息,其中一种是通过环境变量传递,然后内部还要有一个对应机制进行转化,这其实是非常麻烦的过程。但是现在有了ConfigMap之后,就只需要将原先的配置文件导入到ConfigMap中就行了。
迁移中遇到的其他问题
关于CI/CD
我们在做迁移的时候采用的是Jenkins来实现CI/CD的,然后通过Helm来实现软件包管理,Helm是Kubernetes的官方子项目,作为企业内部的应用管理是非常方便的,它使得开发者不用再去关注Kubernetes本身而只需要专注于应用开发就够了。
时区的配置问题
从官方下载的镜像都会有默认时区,一般我们使用的时候都需要更改时区,更改时区的方式有多种,这里简单说两种。一是将容器镜像的/etc/loacltime根据需要设置为对应的时区,二是采用配置文件中的volume挂载宿主机对应的localtime文件的方式。推荐采用第二种方式。
外部网络访问Service
在没有Ingress的时候我们是使用内建Nginx容器来转发集群内部服务,现在则是通过Ingress转发集群内部服务,Ingress通过NodePort方式暴露给外网。
最佳组合
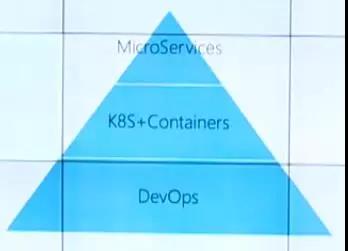
上图展示的是Kubernetes的最佳组合,它以DevOps作为基础,上层是k8s加上Containers,顶层构筑的是微服务应用。这样的组合带来的不仅是一个容器云,更多的是改变了研发流程和组织结构,这主要是受微服务的架构思想影响。
过去完成一个应用的版本发布可能要多人协同,一旦有紧急发布的时候就会发现这其实是非常笨重的。但是如果是基于微服务架构做的应用,往往一到两个人就可以维护一个微服务,他们自己就可以决定这个微服务是否独立部署上线。
关于微服务和Kubernetes还有一个优势必须要强调,配合CI/CD开发人员终于可以不再考虑部署环境的细节了。