








想迁移现有的数据仓库到Hadoop平台?想在Hadoop上重用其他RDMBS的SQL技能?有何方案能帮助您解决这类问题,答案是IBM Big SQL。
Big SQL是IBM的SQL on Hadoop解决方案,它充分利用了IBM在RDBMS领域数十年的经验,是业界最成熟、最完善,性能好的SQL引擎。除此之外,Big SQL还具有其他产品无法比拟的的SQL兼容性。正是这种兼容性,Big SQL成为Offload和整合RDBMS的终极平台。
在BigInsights 4.2中,Big SQL能兼容DB2、Oracle、Netezza的绝大部分语法。这意味着,您可以轻松地利用BigInsights运行现有的SQL工作负载,轻松地在Hadoop平台上继续使用您最熟悉的SQL处理数据。
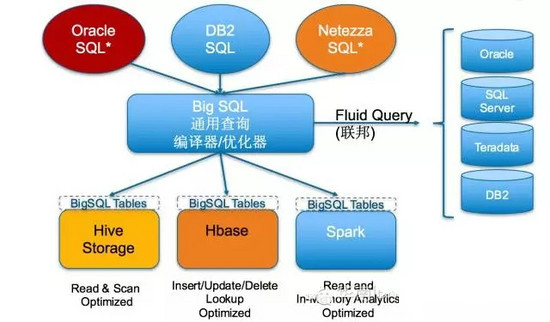
Big SQL支持将表建在HDFS(共享Hive的HCatalog)上,支持各种开源文件格式(如Parquet,ORC等),专门针对Read和Scan操作进行优化;支持创建基于HBase的BigSQL表,为Insert/Update/Delete/Lookup并发读写操作而优化;Big SQL还能与Spark共享元数据,使得Spark SQL能够访问Big SQL表。
通过联邦技术,Big SQL能一个SQL语句中同时访问(包括读取和关联等各种SQL操作)本地的Hive/HBase表和其他远程的数据库的表。
支持Oracle、DB2、Netezza的SQL语法,轻松兼容已有的SQL应用和技能。
由于Big SQL支持ANSI SQL标准,兼容Oracle和Netezza等的通用SQL自然不在话下。让您眼前一亮的是,它能运行其他大部分Oracle和Netezza的语法,如:


当然,这种兼容性不是100%的,但兼容绝大部分常用的语法和持续的改进,Big SQL会让您尝到迁移现有SQL工作负载到Hadoop的便利性。























