








如今,企业的数字化转型和智能升级必谈AI,AI在人们日常生活中的产品和应用也随处可见,如智能音箱、AI相机、人脸支付等。但是,爆炸式增长的数据量、复杂的训练框架和算法,让很多企业现有的AI计算平台变得捉襟见肘:计算效率无法满足业务增加诉求,运营运维成本也居高不下。华为云AI容器为客户提供更高性价比的算力,更简化了平台运维,提升AI计算效率50%,加速了AI计算在各行业的落地和发展。
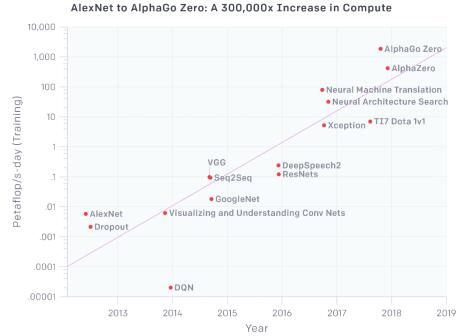
计算量6年增长30万倍,AI平台扩容成本高
OpenAI分析报告显示,从2012至2018年的6年时间,AI训练使用的算力增长了30万倍,是同时期摩尔定律增长量的5倍。这意味着,要保持计算速度不变,不能单单依靠芯片能力的升级,还必须增加计算设备投入。而专业GPU服务器配以高速网络、高速存储等设备,单台平均成本在100万左右,价格高昂,大部分企业难以承担。
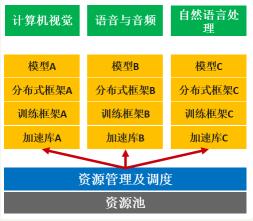
系统日趋复杂,AI平台运维难度激增
首先,不同的业务需要不同的AI训练框架、模型、加速库,如何在统一平台上管理不同的训练框架和模型,如何将线下训练快速部署到生产环境带来巨大挑战。
其次,AI训练和公司业务使用不同的资源管理工具,使得运维团队需要掌握和使用多种资源管理工具,保障GPU利用率,增加运维复杂度。
再者,GPU在集群内被不同业务团队共享,团队间的资源协调也会耗费不少精力。
公有云+容器化:AI计算平台建设的必选之路
面对上述问题,各企业开始着手构建基于公有云和容器的AI计算平台,基于公有云的容器平台,能给客户带来什么样的好处呢?
更快速的获取算力资源
面对AI计算需要的超大规模算力,自建IDC扩容周期长、一次性投入大,后期维护成本高,采用公有云,可以即申请即用,快速补充企业IDC算力的不足,同时具备更低的使用成本、无需关注基础设施维护、避免资源闲置造成浪费等优势,成为了客户扩充算力的最佳选择。
降低日常使用和运维难度
用户搭建深度学习训练环境,需要准备带GPU的机器、安装Python、TensorFlow、GPU驱动等,如果要从开发环境到测试环境,再从测试环境到生成环境,涉及环境迁移过程中需要花很大精力来保证环境的一致性。
容器带来的标准化打包能力可以提供了绝佳的解决方案,将相关软件一并打包到镜像中,一次构建,即可在不同平台上运行,极大降低安装、部署的复杂度;同时各容器间相互隔离,可实现多训练框架并存,而且每一个框架都可以独立进行升级而不会影响其他业务,降低的日常运维的难度,让客户可以将更多的精力集中在AI训练上。
但是,我们在与用户交流过程中发现,用户虽然认可公有云+容器的模式,但是在公有云上自建一套容器化的AI计算平台,对部分用户仍存在较大的技术门槛,尤其是那些尚未接触过容器的用户。华为云就此推出了面向AI计算场景的容器服务——AI容器,并于2018年在华为全联接大会发布,今年我们对AI容器进行了升级,在性能、易用性、可运维等方面都有了很大的提升。
华为云AI容器:更易使用和运维,提升AI计算效率50%
开箱即用 免除基础设施运维
AI容器采用华为云容器实例(CCI)作为基础设施层,得益于CCI的Serverless架构,用户完全无需关心主机的创建、管理、运维,而只需要在使用时申请所需要的算力资源即可(算力类型、CPU核数、内存量),省去了基础设施的日常运维工作,用户可以更加专注于AI计算本身。
高效调度,快速获取海量算力
AI容器基于全新的Volcano平台进行任务调度管理,Volcano是华为云高性能批量计算平台,具有更高的调度性能,高可达1000容器/秒,将算力获取的效率提升近10倍。
同时,有了Volcano的加持,AI容器还可以基于拓扑和资源亲和进行任务调度,根据策略将关联任务调度到同一物理节点或二层网络内,极大的提升了AI训练过程中任务间通信及数据交互的效率。
秒级计费,资源性价比更高
AI训练时客户需要快速、多次计算进行迭代,会对资源进行频繁的申请、释放,AI容器采用按秒计费和套餐包的计费方式,真正做到按使用付费(PAYU),避免客户采用包周期等方式购买资源后,利用率不足而造成的浪费。
开放生态 支持主流训练框架
随着AI平台容器化的深入,大量训练框架都已发布其容器版本,AI容器目前已支持Tensorflow, Caffe, Mxnet, Pytorch, MindSpore等近十种主流训练框架,用户可以将训练代码平滑的迁移上云。
多样算力 用户选择更加灵活
AI容器的能提供昇腾、鲲鹏、x86和GPU等类型的算力资源,用户可以实现一套平台运行不同类型的应用,根据应用特点灵活选择算力资源,达到资源的最优配置。





















