








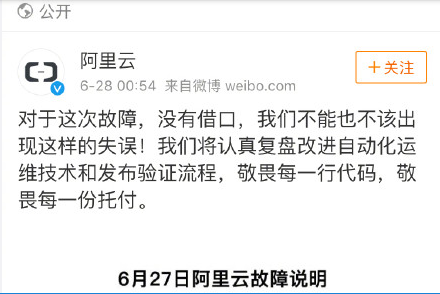
6月27日晚,有大量用户反映阿里云出现连接问题,很多用户在实例上执行操作之后没有回应,在6月28日凌晨,阿里云发出公告,表示问题是运维和工程师的失误导致,现已恢复。无独有偶,chromecast和Google Home也在同一日也出现了服务器问题,谷歌公告告知,将在6小时恢复。
如今,绝大多数人都非常依赖互联网,服务器的宕机就像鱼没有了水一样。对于用户来说,每一分钟的宕机都是巨大的经济损失。回顾历史,很多宕机都造成了非常大的社会影响。在2013年,雅虎对邮箱进行了一次升级,很多用户反应在升级之后,服务器不稳定,并丢失很多邮件。在2个月后,雅虎承认1%的用户出现问题,其直接影响100万人,时间长达数周甚至数月,让很多企业和用户的沟通出现问题。
在2015年9月,业界份额第一的亚马逊云出现过宕机,最严重的宕机事件要属2013年8月22日的纳斯达克停摆,由于交易所使用的备用服务器出现软件BUG,导致停摆3小时,造成的经济损失不可估量。
纵观绝大多数的云服务宕机事件,不可抗原因极少,大部分都是机器本身的故障或者软件升级的问题,选择成熟的硬件平台和后期运维显得非常重要。云服务器之所以称之为云服务,就是因为服务商有成熟的整套解决方案,稳定而且售后完善,能处理一些意外情况,尽量加快服务器的恢复时间,减少客户的损失。云服务们在价格战的同时,是否可以用户的使用体验和品质?恶意的竞争有时候对用户来说并不是好事。























