6月27日下午,阿里云因为“运维上的一个操作失误”,导致一些客户访问阿里云官网控制台和使用部分产品功能出现问题。
作为中国大的公有云厂商,阿里云的服务出现问题肯定影响面比较大,但是产品或者服务出现一定的问题,对于云计算厂商而言也是常见问题,各家厂商能够做得是将故障或者宕机时间缩小到最短。
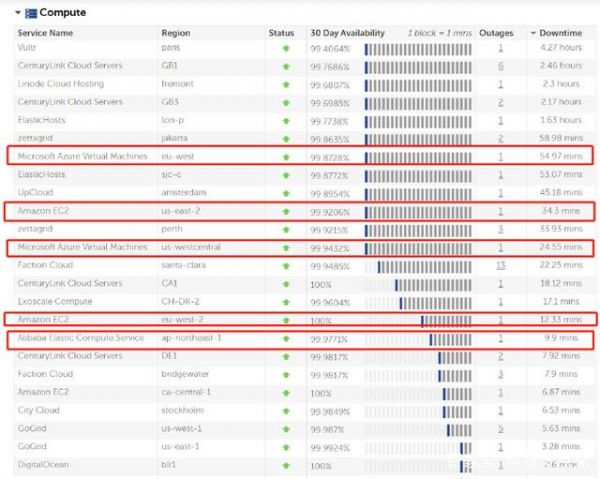
CloudHarmony对宕机时长的统计
知名市场研究机构Gartner旗下的CloudHarmony网站通过对48家云服务商的宕机故障发生的次数和时长的监测来追踪服务商的服务运行情况。
虽然阿里云出现了一些问题,但是从CloudHarmony网站的监控数据来看,过去30天内,阿里云的云计算服务表现好于微软Azure和亚马逊EC2.根据CloudHarmony的统计数据显示,全球前几名的公有云厂商中,微软Azure欧洲的一个可用域出现了54.97分钟的宕机,而亚马逊EC2在美国东部的一个可用域宕机34.3分钟,阿里云位于日本的可用域出现了9.9分钟宕机。
CloudHarmony的统计的服务包括云计算、云存储、CDN以及DNS服务,从多项指标来看,微软Azure的宕机问题比较突出一些,其他厂商则基本没有出现宕机问题。
人为和客观因素都会导致云计算厂商提供的服务出现宕机等问题,这属于运营过程中的正常现象。过去几年,全球主要的云计算厂商都出现过不少区域运营中断的问题。
去年3月,亚马逊云端资料储存服务S3(Amazon Simple Storage Service)位于美国维吉尼亚州北部的资料中心,出现大规模故障,波及Giphy、Medium、Slack、Quora等上千家使用亚马逊云端服务(AWS)储存资料和提供线上服务网站,历经4小时才抢修完成。今年6月,Google Cloud因重复分配IP地址,导致数量很多的虚拟机瘫痪。
但是需要强调的一点是,如果某家云计算厂商拥有的可用计算域较多的话,它宕机的时间累计量也会更长。因此,对于客户来说,云服务的正常运行时间才是衡量可靠性的最关键因素。