








随着云计算、大数据的不断发展和成熟,人工智能引发了新一轮的技术变革,成为未来信息技术发展的风向标,计算力作为人工智能的三要素之一,GPU/FPGA芯片的加速能力也得到业界的广泛关注和重视。基于此,国内云服务商开始发力GPU云主机市场,加大对基础设施的投入。

由于FPGA与GPU相比,FPGA使用门槛较高,因而GPU应用更为广泛。目前,GPU云主机主要用于机器(深度)学习、图形处理、科学计算、视频编解码等场景,为了顺应市场发展需求,由中国信息通信研究院主导的可信云评估体系新增了对GPU主机的评估标准,相对于云主机,GPU云主机在服务形态仍有所差异,性能无疑是用户重点关注的指标之一。
首批评估对象囊括了国内公有云厂商的第一梯队, 阿里云、腾讯云、华为云、百度云、天翼云、UCloud六大厂商齐聚首,堪称行业水平实力担当。为了更好的让用户认识和了解GPU云主机,本次评估重点考察了大家关注的指标和GPU云主机特有的指标,如服务功能、资源调配能力和性能。 GPU云主机目前应用于机器(深度)学习占据了较大比例,今天主要讨论基于深度学习的性能评估测试。
资源选型
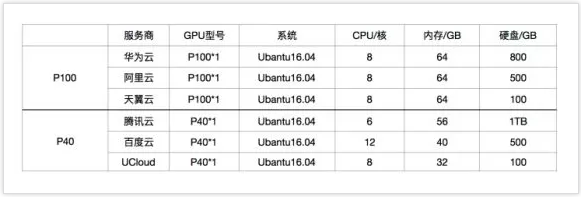
目前主流的GPU型号主要是Nvidia的Tesla K、M和P系列,本次评估的资源选型基于P系列两个型号进行,6家厂商分为P40和P100两组,在资源规格上,阿里云和腾讯云可同时提供A卡和N卡。GPU性能指标官方数据主要体现在单精度和双精度,对用户不具有实际的参考意义, 模拟用户进行机器学习训练,直观反映GPU主机性能,更加贴近用户需求。
深度学习模型
深度学习的训练主要依靠模型和数据集,国际上比较具有代性的训练模型主要有:AlexNet模型、Cifar10模型、MNist模型、ResNet模型,此次评估选择其中三个机器学习模型,数据集上的选择,ImageNet数据量相对权威,但是有数据量过大,国内镜像较少,不适合用于短期的测试验证。本地评估测试主要基于机器学习模型默认数据集或数据精简集。以下是常见的深度学习模型:
01 AlexNet模型:
是Alex和Hinton参加ILSVRC2012比赛的卷积网络模型,网络结构是开启更深CNN的开山之作,其对CNN的一些改进成为以后CNN网络通用的结构。
02 Cifar10模型:
是典型的卷积神经网络结构,包含相应的卷积层,池化层,修正线性单元以及最顶层带有分类器的归一化采样层。数据集为一个使用非常广泛的物体识别图像数据集,CIFAR-10数据中包含了60000张32×32的彩色图像,其中训练集50000张,测试集10000张。
03 Mnist模型:
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片,包含60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。
04 ResNet模型:
深度残差网络。该网络对residual block和shortcut connection的引入,使网络能够达到更高的层数并且不会发生网络退化现象。ResNet是由KaiMing He在2015年发表,并基于该模型获得了当年ImageNet detection,ImageNet localization,COCO detection等多个比赛的冠军。
测试环节
在实际测试环节,首先要做的是搭建环境,如GPU驱动、CUDA等必要条件,其中部分厂商已经在操作系统镜像集成了GPU驱动,减少了安装的工作量;在配置深度学习库TensorFlow时,需要正确安装对应版本的CUDA、cuDNN、Python等环境,也有厂商帮用户提供好了容器的镜像文件,细节体现差异,真正做到省时省力;结果处理环节,首先保证足够多的数据量,将各个模型测试结果保存到本地文件,去除首末端噪点数据,再对数据进行去除坏值,求大、最小值、平均值、中位数、方差等数据,最终将数据可视化。
应用案例性能测试
除了使用经典机器学习模型进行性能测试之外,同期举办的云计算性能创新大赛广泛征集了高校优秀案例,对GPU云主机性能进行了验证。案例的取材包含了大型仿真、机器学习、科学计算等热门应用场景,其中来自清华和兰大的应用案例得到了专家评审的一致高度认可,体现了学术界和产业界的完美结合,成为云计算助力行业应用的成功典范。
目前首批评估的测试工作即将接近尾声,结果也将于3月22日的云计算开源产业大会高性能分论坛公布,如果您关注高性能计算、关注GPU云服务,一定不要错过这此盛会。






















