








随着云计算和大数据的普及,越来越多的IT公司选择将自己的大数据解决方案部署在云上面。云计算和大数据的结合带来了什么便利呢?一个典型的大数据云又是如何设计和部署的呢?
下面我们以Google Cloud作为例子,讲解在工业界里边是如何实际应用云。
Google Cloud
Google作为分布式系统和大数据的领导者,开发了众多跨时代的产品。几乎每一个Google的产品,写出一篇paper就可以创造一个开源社区的。
比如MapReduce发布之后,开源社区根据Google的一篇论文开发出的Hadoop,BigTable发布之后,开源社区又进一步开发出Hbase等等。可以说没有Google的创新,就没有现在开源社区的繁荣。
而Google又把自家的产品,都放在Google Cloud上面,形成了丰富多彩的产品线,吸引了非常多的大大小小的公司如Snapchat等来使用。
Google App Engine (GAE)
我们都知道Web项目都需要大量的Web Service以及为之服务的运维系统。Google在云计算领域首次尝试的就是Google App Engine (GAE),相对比当时的Amazon EC2,GAE只需开发者上传软件代码,其他部署将由Google完成。
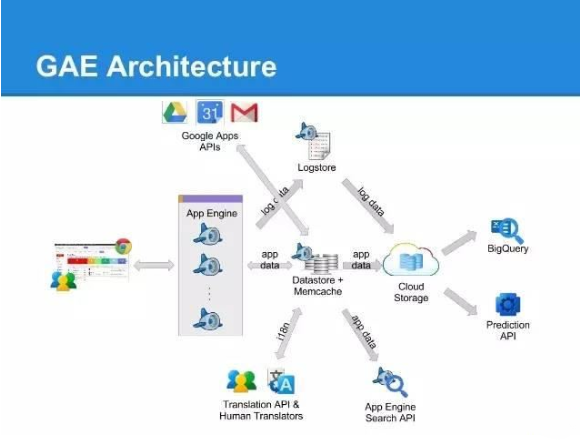
用户只需要熟悉后端语言开发即部署大规模的集群。Google今年更是推出了GAE Flex,可以帮助用户实现auto-scaling,用户不再需要自己部署负载均衡的服务了。大部分中小企业的网站几乎都可以无缝衔接到GAE上。
BigTable
BigTable的底层是注明的Google File System (GFS),他实现了数据中心级别的可靠的分布式存储。
也是最早的NoSQL数据库的一种。各种网站如果有需要永久存储的数据,一般都可以存放在BigTable里边,Google Cloud会自动帮你做replication,分布在不同的服务器节点里边,这样实现了可靠的分布式存储。
Dataflow
Dataflow的底层实现利用了大名鼎鼎的MapReduce的升级版Flume。
Dataflow特别方便进行大量的批处理,举个例子来说,比如要把所有的用户数据里边的格式都升级一遍,用GAE或者其他service是很难实现的。
Dataflow也提供了特别多的接口,诸如BigQuery, Datastore, BigTable等等也是为了方便各种批处理。最近Google还提供了streaming(流服务)版本的Dataflow,可以实现持续不断的批处理。
BigQuery
BigQuery相当于是Cloud version的SQL,可以方便使用各种复杂的查询语言查找数据。这个尤其适合数据分析师进行各种数据分析,几乎各种SQL的语法都是支持的。
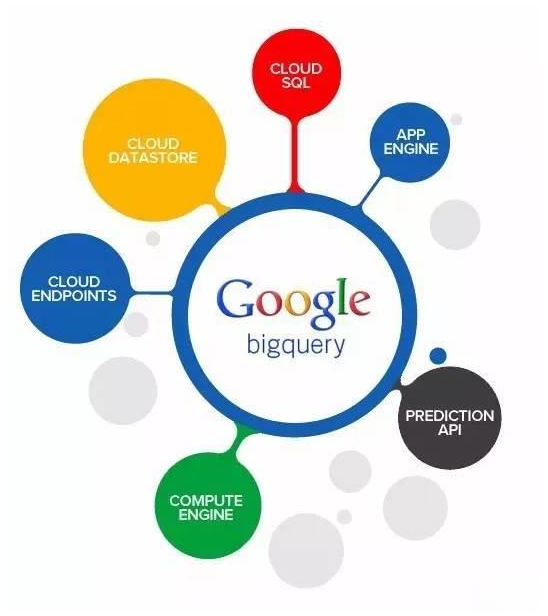
但是BigQuery在scaling上并不如BigTable,并不是面向用户的,所以并不适合直接用来存储用户数据。只适合做一些离线分析,数据来源很多都是Dataflow从BigTable里边dump出来的一些拷贝。
其他服务
Google Cloud还有非常多的其他服务,诸如支持消息队列处理的Pubsub,支持缓存的Memchace,支持Monitoring的Stackdriver,等等完整的构成了一个企业数据云所必须的各种服务,可以满足大到Snapchat级别,小到各种startup的不同业务需求。























