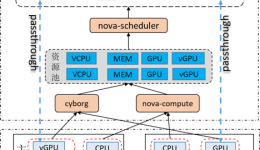
大家看到这张表这是今天OpenStack Nova的调度。第二,基于资源计算节点上有多少I/O和多少带宽可以用,之后根据大家的需求对设备的支持,Nova自己能够测一下CPU利用率。第三,针对Fit。最后是自己写条件要不要在这台后端运行,这张表是计算全值的动作,从前面的表上大家可以有一个感觉,特别零散,把这些做成表以后看起来还非常乱,这就是开源社区的特点,我有一个需求,我加一个future,我有一个不满意的地方就拿去修一下,没有总体规划。再往下面做的时候,可能这个事情做起来比较麻烦,也没有办法维护,从这张图实际上是代码实现上的大致类图,大家可以看一下整个流程做的蛮诡异的。他先把一些不满足条件的过滤掉,对剩下的做了优先序的排序,之后再往下类层次结构,如果你自己写一个调度器满足自己要求的话,就在后面接一个就可以了。所以听起来也不是那么特别的难,如果你有上游代码不满足你需要的话。
另外中间还有一个项目叫做GANNTP,是尝试在OpenStack里做一个比较通用的路由器,这个项目做了一两年就死掉了,因为它是拉出去单干了,没有跟Nova密切配合,Nova有自己的调度器还在往前做,GANNTP还在自己往前做,所以社区的决定是调度器不能自己拉出去另起炉灶,要从Nova里面找。所以一年前社区开始做调度器,对整个上的调度做了非常高度的抽象,我有什么资源,用一个表来表示,我已经分配了哪些,然后提供一些资源,每个资源有一个名字,最小值多少,大值多少,每次往上可以涨多少,这些都可以搞。对于不能计量的资源,比如就是X86机器的区别,还不好用数字表达的话,这种可以用另外一种PY6表达方式,用这样新的概念就可以表达你所有能够想象的需求。这是非常有野心的项目,也很值得关注。至于说这个是不是将来能一统天下也不知道,不过有Nova这个团队的强力支持,这个事做成的概率还是要高很多。
接下来我们看一下另外一个K8S,它里面做调度的时候做法,它做了很多类似labor的东西,也就是打标签,仍然是分几大类,一种是纯labor,另外是有统计数,有几个CPU,有多少内存。像GPU最近也加进去了,但是GPU只能支持0、1,到2就搞不动了,所有的需求都是加到哪儿算哪儿,这个是蛮令人失望的。还有这上面做的比较有趣的是,在它的调度里把存储做进去了,这个是OpenStack里面的弱点。OpenStack做调度的时候是不考虑网络,不考虑存储的。K8S调度器也跟Nova长得很像,第一步是做过滤,第二步是根据不同象限和维度做优先级排序,如果排出来是好几个,我就随便选一个,基本上这个思路没有太新鲜的东西。K8S因为实现是编译完了以后发布的,所以对它进行扩展和OpenStack的还不一样,OpenStack随便在里面改两行代码,重新启一下,谁都不知道就把这个事干了,但是K8S不一样,是编译完才能运行,所以在上面扩展有所不同。所以在K8S做调度扩展是给了这么一种做法,你可以写自己的调度器,但是作为K8S自己调度器的扩展是外面随便搞。
oVirt可能在国内外得不多,但是我一个朋友在国外参加活动的时候,发现oVirt用得比较多,是比较成熟的东西,至于是不是语言,这种定性的评价我们不去讲,我们先关注一下它的调度做法。没有什么惊喜的,仍然是我有一堆机器之后,你给我什么样的条件,然后满足这些条件,它做得比较好的一点是在扩展性上支持多种语言,你去oVirt网站上也可以看到有一些评价,可能用Java是比较好一些。oVirt Filters对于云来说就有点太细了。下面这张表是过滤出来这些机器以后,基于不同维度再去做全值的计算。
最后一组我们看一下Mesos,我对这个不是特别感冒,我并不认为Mesos是适合cloud的,这也是个人看法。Mesos可能在座有专家对这个比较熟悉,Mesos是自己不做调度,他只负责资源管理,把资源包放上去,自己不做调度。它在做资源描述的时候,比如说在每个Mesos可以配,有多少CPU、GPU,有多少资源可以供应这件事都可以做了。接下来做调度的话,我稍微看了一下Mesos,常见的评价是Mesos比较适合运行时间比较长的应用。所以大家用Mesos定制调度实现的时候,可能就会遇到一些困扰,你理解它本身就有点费劲,它在底下那些资源表达能力也就那样,反正你自己随便写。
最后我尝试给一个讨论,纯粹的个人观点陈述。我们看调度本身是一个什么样的问题,我们经常写代码,每天在那儿自己high得不得了,要修多少bug,往往可能就忘了自己为什么干这件事,我尝试对调度这件事情做总结,我们为什么做调度,首先从上往下看它都有自己的资源需求,下面不管用什么平台,中间是资源分配或者调度的过程。那上面资源本身需求有哪些因素,你要做一个宇宙第一的调度器的话,你要讨论哪些因素。这个需求本身可能是hard,就是不给我两个CPU就起不了,其他的维度还有是这个需求是不变的,还是没法预测的。那么负载什么时候到,它是长得胖还是瘦,不知道的,它是不是有对特殊设备的需求,比如说我去玩社区的时候,或者搞认知计算还是人工智能,深度学习,我要玩GPU什么的,没有GPU这事就干不了,而这种调度能力是不是调度器能够支持,下面能不能调配上来也不知道。一堆服务给你的时候,你把它给到你的机制上,让它们自动连接好,并且能够彼此发现对方还能够工作,这个也不容易。从下面我们看资源贡献的角度,我看论文上有一些分类,一种是随时要随时给,第二是你要的时候先说,第三种是有,但是我不保证,你现在用就用了,随时都可能完全没了。第一种你可以单独的给你CPU,你还是干不了活。而且你还要考虑运维造成的资源中断等等因素。那么在中间要考虑哪些问题,要考虑资源利用率,要考虑既然是虚拟化平台,那虚拟机是不是可以搬来搬去,你要考虑完成时间,这些都是为了讨好你的用户,都是为了提高性能。如果你做得更好一些,你在调度的时候还要考虑怎么提高服务质量。只有在学术圈里才考虑你的调度器策略够不够公平,调度器本身是不是足够快,是不是能够skill做预测。我个人比较失望的是,到目前为止我没有看到任何一个调度器cost,感觉我提供了资源所有人拿去都是不花钱的。其他的一些Factors技术,我调研发现过去一共有1600多篇论文,大家提出了90多种以上不同的解决方法,但是真正落地的不多。第二,因为我们真正的是商用,你是不是可以考虑让用户做协商和拍卖,把资源充分利用起来,发挥它的价值。
我们现在看到的状况下,这个领域研究非常活跃,也不知道出了多少博士生,出了多少博导。如果你的云不管是自己用,还是别人用,如果真的有好的调度的话,真正的是很多东西都可以一刀切。另外,可能列了那么多表,从不同框架里看到不同的算法,可能真的没有一个是符合你的需要的,然后更重要的一点是,你自己都不知道你自己想要什么的时候,这件事就没法解决了。因为我还是做以测序为主,希望在社区里大家集思广益,不管你有什么想法,我们是不是可以拿出来共同探讨,把这件事情做得更好。谢谢大家!