








目前,高性能计算市场正处于技术转型期 —— 向“Co-design(协同设计)”的方向过渡。就像很多文章中所探讨的那样,这种转型的出现是为了打破当前基础设施和应用的性能瓶颈,既由存在已久的多核CPU以及CPU为核心的系统架构所带来的性能瓶颈。
那么,为什么多核CPU反倒成了性能瓶颈的原因?为了更好的理解这一点,我们来回顾一下此前的单核CPU时代。在那时,CPU的核心频率是最重要的参数——因此当时人们提升系统性能的办法就是通过提高CPU主频,并将网络功能减少(包括网络适配器和交换机)。每一代新产品的发布都会带来更快的CPU以及更低延迟的网络适配器和交换机,这是当时计算机性能提升的主要模式。然而,这个模式不可能一直持续下去——由于功耗问题的限制,CPU主频不可能无限提高。因此,我们并没有一味地再去提升频率,而是采用了并行多核CPU,从而让处理器能够在同一时间执行多个进程。从此,我们提升系统性能的方法,不再是简单的提升单核运行速度,而是通过多核来同时处理更多的指令。
这种增加CPU核心数量的新模式大幅增加了互连系统的负担,另外这也让网络互连变成了系统性能的主要因素。准确的说,决定系统性能的关键,就是所有CPU进程的同步速度,以及CPU进程之间数据包聚合和分发的速率。
不过,与大环境的通信模式相比,互连延迟的改进所能带来的影响也是微乎其微的。目前,InfiniBand交换机的普遍延迟为90纳秒,InfiniBand适配器的延迟则是100纳秒。CPU处理的通信框架,比如MPI集体通信,它的延迟在几十微秒范围内(1微秒=1000纳秒)。这种不同数量级的通信延迟差距,使得互连系统方面的延迟优势微乎其微——即便再降10、20、40或50纳秒,与CPU进程间的通信延迟相比可以忽略。换句话说,对HPC的未来而言,某些公司所提议的将网络适配器与CPU合并,以减少几纳秒延迟的想法太过异想天开。
也许有人会好奇这和卸载(Offloading)与加载(Onloading)的PK有何关系,其实关系非常大。过去,卸载与加载之间的争论主要集中在CPU效率方面。研发出一项基于卸载架构的互连技术的难度和复杂度都不容小觑,但其回报也不菲——它能够让CPU从网络管理中脱身,进而能够轻松提升40-50% 的CPU与系统利用率。而基于加载(onloading)架构的互连技术开发则相对简单的多,它只不过是一个简单的通道,所有的网络操作仍然必须由CPU来管理和执行;从应用的角度来看,一半的CPU资源都被浪费了。
此外,基于任务卸载(Offloading)的架构能够让像RDMA(远程内存直接访问)这样的技术变得可用,而这是加载(Onloading)架构无法做到的。我们已经见过无数应用性能展示的示例,这些示例无一不证明了基于任务卸载解决方案对比Onloading产品的显著优势(比如DDR InfiniBand vs. Pathscale InfiniPath 和 QDR InfiniBand vs.QLogic/Intel TrueScale)。
如今,基于任务卸载的架构不光拥有绝佳的性能和性价比优势,更是解决系统性能瓶颈的关键——除非采用智能的互连和卸载技术,否则系统将很难再继续高效的扩展下去。
随着进程数量的持续增长,IT人士可以通过并行的编程手段来解决科研与制造领域中的复杂问题,也因此,进程间通讯的重要性日益凸显。和“乒乓操作”(Ping-Pong)的网络延迟相比,更关键的是复杂通讯的延迟——集群通信(collective)或数据聚合操作。在CPU上执行这类操作都会导致其性能受到极大极限,从而无法进一步加快速度。实际上,唯一的有效解决方案就是当数据在集群内传输过程中就执行此类操作,暨数据传输中通过互连设备自身功能(交换机、适配器)进行复杂通信的操作。该方案基于全球Co-Design(协同设计)架构开发,它将帮助我们加速迈向百亿亿次计算。
这一技术趋势不仅将影响高性能计算,还将改变数据分析、机器学习以及其他数据密集型应用和基于数据搜索的应用领域的发展。曾经在21世纪前期大放异彩的CPU多核并行解决方案在今天已经成了提升系统性能的瓶颈,新型智能卸载互连技术才是新的救星。智能互连解决方案将成为新的协处理器,因此它们也将是高可扩展计算的关键因素。
重新回到应用性能和系统投资收益率(ROI)的讨论。关于EDR InfiniBand和英特尔Omni-Path之间的性能对比与此前两种不同互连技术的对比应该基本类似。虽然目前关于Omni-Path的可用系统很少,但我们已经可以看到在不同高性能应用实例中所表现出的系统性能差异,例如WIEN2K、Quantum Espresso和LS-DYNA。
WIEN2k可让用户采用密度泛函理论计算固体电子结构。它是一个包括相对论在内的全电子方案,已授权2000多个用户组使用 。Quantum Espresso则是一个开源计算代码的集成套件,它可用于实现电子结构的计算和纳米级的材料建模。它主要基于密度泛函、平面波和赝势等理论。LS-DYNA是由Livermore软件科技公司(LSTC)开发的一款先进的通用多物理仿真软件包。这个软件包不仅能够继续升级用于真实复杂世界问题的计算,它的核心功能还可以应用显性时间积分方法解决高度非线性瞬态动力有限元分析问题。LS-DYNA主要用于汽车、航空、建筑、军工、制造以及生物工程等行业。
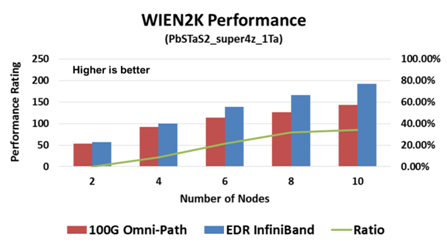
WIEN2K软件性能比较(数值越大越好)
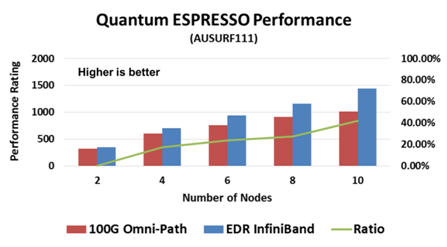
QuantumESPRESSO性能比较(数值越大越好)
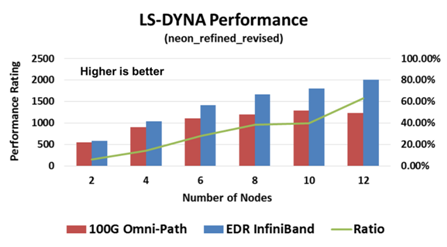
LS-DYNA性能比较(数值越大越好)
在以上这三种评测中,我们可以看到EDR InfiniBand智能网络均表现出了显著的性能优势。值得一提的是,在整个系统的性能差异对比中,InfiniBand的性能优势在35%~63%之间。还应指出的是,这些测试系统的规模较小,随着系统规模的扩大,其性能优势比例也会更高。
此外,就像LS-DYNA示例中所示,只采用6个节点的InfiniBand性能表现就已经超过了采用12个节点的Omni-Path,即InfiniBand以一半的系统规模即能实现比Omni-Path更高的性能。
总结:基于卸载的智能互连系统的性能优势显而易见,而InfiniBand和Omni-Path的对比评测结果也是亦然。






















