








本文是CoreOS近期对Kubernetes扩容性的一些针对性试验、检测和研究,分析并且得出了对Kubernetes集群部署和pod吞吐量等Kubernetes集群性能问题、扩容性问题上一系列的尝试和见解。该文章回顾了从硬件到软件层面采用缩小范围以及使用Kubernetes提供的端对端API性能指标和使用benchmarking作为基准工具等手段进行对建立不同规模集群过程中的pod吞吐量测试,从而发现Kubernetes集群调度器性能的潜在瓶颈和潜在解决方案。
扩容性对任何一个分布式系统的成功而言都是一个重要的因素。在CoreOS,我们非常喜欢Kubernetes,希望能够通过对上游的贡献来推进这个项目。去年11月,我们组建了一个团队,专门研究Kubernetes的扩容性。我们设定了一个目标来检测和理解Kubernetes集群的性能,从而获取集群在工作量很大的情况下的表现性能,来获取Kubernetes集群的性能问题大概在什么地方。
很快我们就开展了这方面的工作,我们发现了一系列的瓶颈。通过解决这些瓶颈,我们把Kubernetes调度基准在1千个节点上调度3万个pod的时间从8780秒降到587秒。在这篇文章里,分享了我们是如何获得这个超过了十倍的性能提升,并且希望能够抛砖引玉,让社区可以进一步提升Kubernetes的扩容性。
Kubernetes架构概览
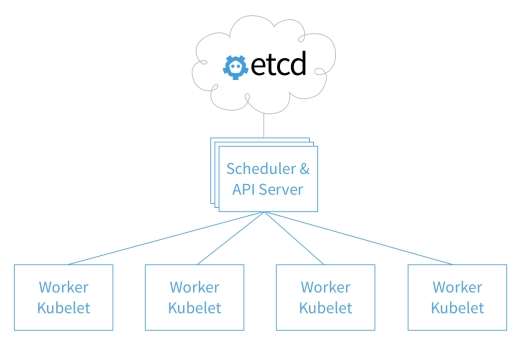
为了理解和提高Kubernetes的性能,我们首先需要建立一个适于当前能力的基线。一个Kubernetes集群是由一整套控制管理集群操作的API节点来组成的,API节点跑在工作节点上,应用的pods也同样跑在这些节点上。我们最初把目光聚集在控制层部件,因为它们参与了集群层面的每一个调度操作,这是我们理解性能最有可能提升的地方。Kubernetes的构架参见下图。
对Kubemark的试验
Kubernetes社区最近推出了Kubemark,用来测试控制层部件的性能。Kubemark模拟了工作节点,可以在一个单独的CPU内核上模拟10个真实节点,让我们以最低的复杂度和消耗来模拟大型集群。
我们对Kubemark的第一个使用是做了一个密度测试,来测量在每一个节点上调度30个pod,Kubemark所需要的时间。对一个100个节点的集群来说,有3千个pod需要调度和跑起来;对于1000个节点的集群而言,那就有3万个pod。这些测试结果显示了在不同时期的pod数量。我们所有的测试,集群都是连接在一个etcd集群上,etcd跑在一个单独机器上。

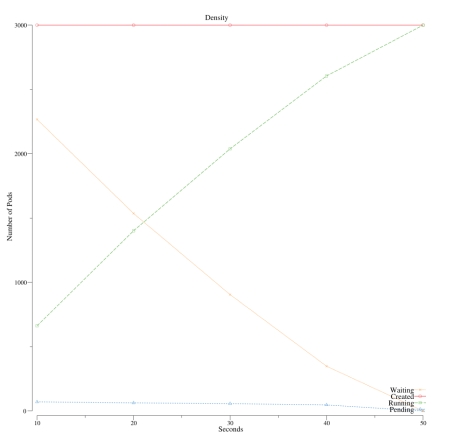
我们以一个拥有100节点的集群测试来开始我们的调查,它在150秒内完成了调度3千个节点的任务。pod的吞吐量在20个pod/秒。为了更好的理解这个日志,我们写了一个plot工具来画图。
下面这个图显示了由 replication controller建立但并非调度的pod,显示了它们一旦被调度到集群的机器里跑起来的时候。
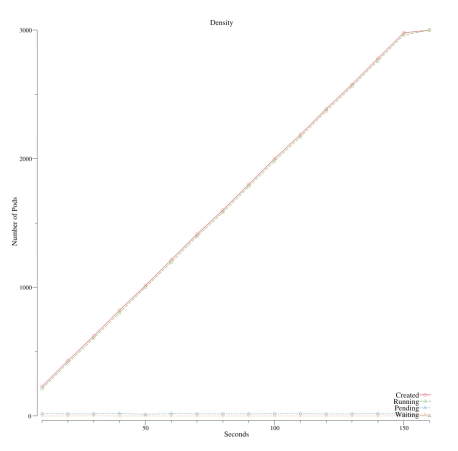
我们很快注意到这个图显示了一个pod创建的线性情况, 在20个pod/秒,看上去很低,说明存在一个潜在的可以提高的瓶颈和目标。我们就从这里开始性能的旅程。
奔向更好吞吐量的旅程
我们脑海中想到的第一件事情是也许硬件资源吃紧了。如果是这样的话,我们可以简单地通过增加资源来提高调度的性能。我们又跑了测试,监控CPU、内存、IO使用率到顶的情况。结果看上去如下:
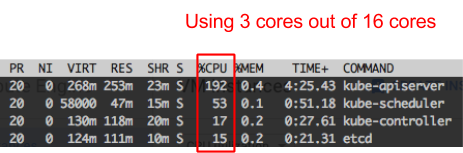
从我们所观察到的来看,没有任何物理资源是被完全使用的。这说明问题出在软件上。
在一个类似Kubernetes这样庞大的代码库中去发现瓶颈,犹如大海捞针。我们需要一步步来缩小范围。幸运的是,Kubernetes提供了大多数端对端API调用的性能指标(被Prometheus这个开源项目所收集)。我们第一步就是在这里面寻找。我们又跑了测试,监控了调度器的指标。结果如下:
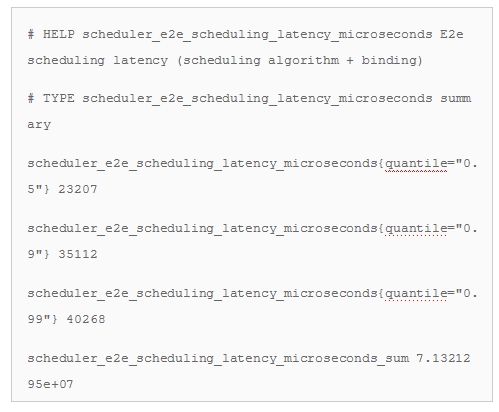
我们发现调度器端到端的延迟达到7ms,相当于140pod/秒的吞吐量,比我们之前测试看到的20pod/秒要高出很多。这说明瓶颈在调度器自身以外。
我们继续通过查看性能指标和日志来缩小问题的范围。我们发现瓶颈在replication controller里。看这里:
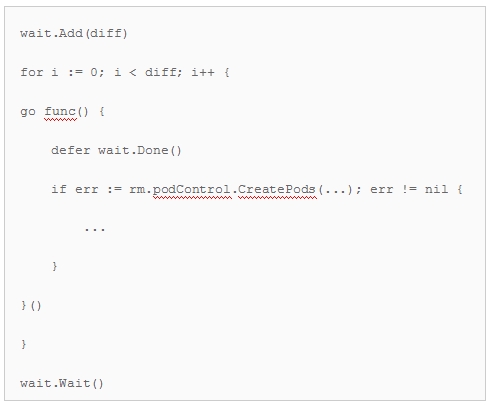
我们打印了日志,发现等到500 CreatePods() 用了25秒。这正好是20pod/秒,但 CreatePods() 的延迟只有1ms。
不久之后,我们在客户端用户里发现了一个速率限制。速率限制是用来保护API服务器不被过度使用。在我们的测试中,我们并不需要它。 我们提高了限制,想看看调度速度的边界。它没有完全解决问题。
结果,我们又发现了一个速率限制,并且修复了一个程序的非有效路径。在那些变化之后,我们得以看到了最终的提高。在100个节点的建立中,平均建立速度从20pod/秒提高到超过300pod/秒,在50秒中完成,平均pod吞吐量在60pod/秒。
目光转向调度器
然后我们尝试在1千个节点的集群上进行提高。然而,我们这次没这么幸运。看看下图:
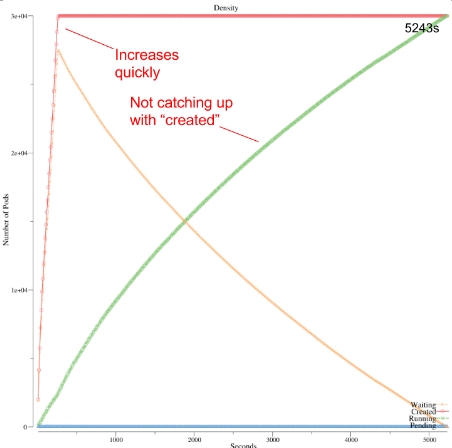
在一千个节点的集群上,花了5243秒来跑3万个pod,平均吞吐量在5.72pod/秒。Creation rate持续增加,但running rate一直比较低。
我们然后又进行了测试,查看调度器的性能指标。这次,调度延迟变成了开始时的60ms,到结束时(即3万个pod)增加到了200ms。结合我们在日志和图表中所见,我们意识到以下两点:
60ms的延迟很高。调度器很可能变成了瓶颈。如果我们能把它降低,这样就能增加调度速度,这样pod的running rate就很有可能变高。 调度延迟随着被调度pod总体数量的增加而上升,这导致了集群pod的running rate的下降。这在调度器里面是个扩容问题。
调度器的代码库是很复杂的,我们需要很细致的归档才能理解调度器在哪块花费了时间。但是,在Kubernetes上面重复同样的过程是很耗时的,我们的测试用了超过两个小时才完成。我们想要一个更加轻便一些的方法来做调度器组建测试,从而集中我们的精力和时间。这样,我们就能写一个像Go unit test那样的调度器的benchmark做基准工具。这个工具测试调度器作为一个整体,而不用启动不必要的部件。更多细节可以从我们的幻灯片(https://docs.google.com/presentation/d/1HYGDFTWyKjJveAk_t10L6uxoZOWTiRVLLCZj5Zxw5ok/edit?usp=sharing)中找到关于调度器性能测试以及在Kubernetes pull request中看到。
通过使用benchmarking做基准的工具,我们高效地工作,打破调度器在1千个节点集群的3万个pod建立上的瓶颈。
例如,在Kubernetes的issue#18126(https://github.com/kubernetes/kubernetes/issues/18126)中,我们有如下pprof (performance profiling)结果:
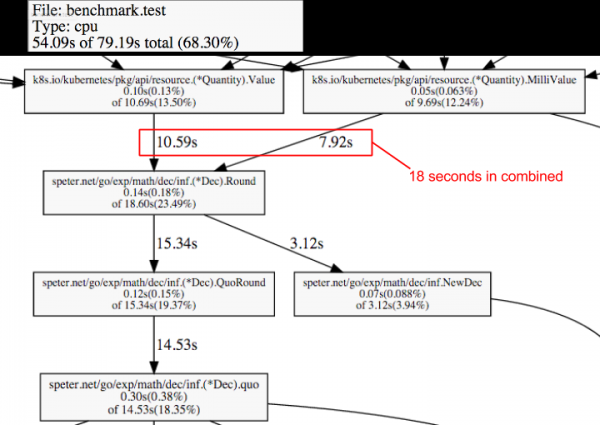
总共的79秒钟内,Round()方法只用了18秒。我们觉得这对于取整而言是失效的。我们用更加有效的实现方式调整了这个问题。结果,我们把对1千个节点上调度1千个pod的平均调度延迟时间从53秒降低到23秒。
这样,我们可以挖掘出更多没有效率且成为瓶颈的代码。在以下的upstream issue中我们进行了汇报并做了提升:
https://github.com/kubernetes/kubernetes/pull/18170 https://github.com/kubernetes/kubernetes/issues/18255 https://github.com/kubernetes/kubernetes/pull/18413 https://github.com/kubernetes/kubernetes/issues/18831
通过使用这些变化,我们获得了难以置信的新能提升——调度吞度量达到51pod/秒。我们又一次跑了调度器的基准为1千个节点集群上调度3万个pod,拿它和之前的结果相比较,请看下图:
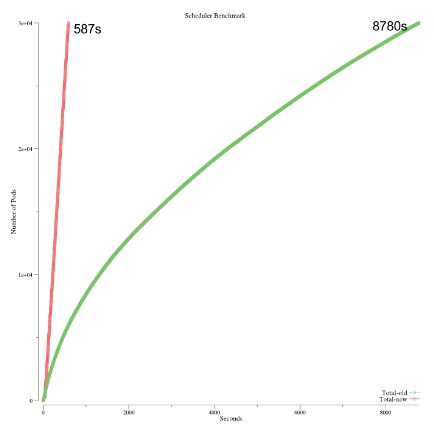
请注意这个过程比跑Kubemark时间更长,有可能是垃圾回收导致的。我们把所有东西放在同一个程序里,Kubemark在不同的进程里来跑调度器、API服务器和controller管理器。但这个区别不影响比较的结果,假设这样是有可比性的。
现状和未来的步骤
通过我们的优化,我们重新跑了Kubemark“1千个节点/3万个pod”测试。结果如下图:
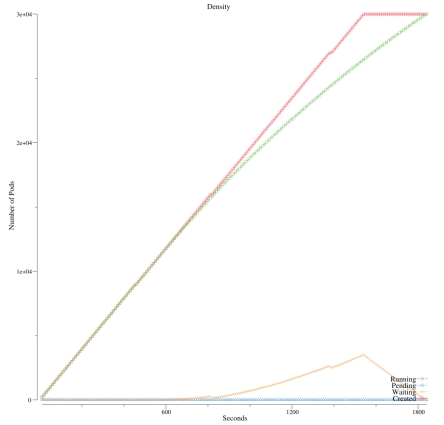
现在,平均pod吞吐量为16.3pod/秒,之前数据为5.72pod/秒。首先,我们看到了吞吐量的提高。第二,这个数字仍然比我们调度器基准的要低。我们确信在这点上,调度器本身不太可能是瓶颈。有很多其他因素,比如远程调用延迟、API服务器中的垃圾回收等等。这可能是一个未来性能提升的下一个探索方向。
扩容Kubernetes
在这篇博文中,我们讨论了我们是如何分析类似于性能指标和CPU归档的实验结果来确定性能瓶颈和提高调度器的。
为了更好的理解调度器,我们提供了一个基准工具,我们用它来验证我们的性能提升。到我们目前的工作位置,我们把1千个节点上调度3万个pod的时间从8780秒降低到了587秒,给Kubernetes发了4个PR。
尽管在这里描述的技术很简单,把我们的想法过程分享给大家会帮助其他人通过把调查研究切分成能够处理的一块一块,从而来debug复杂的分布式系统。
这里重要的是以下几点:
性能指标提供了一个便利和非常亟需的观察系统的视野 使用基准是一个图解性能和发现任何潜在问题的有效方式 画图是一种在一段时间后观察系统比较好的方法
译者:才云科技联合创始人&COO 韩佳瑶
原文链接:https://coreos.com/blog/improving-kubernetes-scheduler-performance.html#rd?sukey=014c68f407f2d3e1b70054f7d5d62ff9043c7ae9852e675c41646ed644e2a15b91af49f6cb635553efeb3f47d78e0371























