








Elasticsearch(ES)作为开源首选的分布式搜索分析引擎,通过一套系统轻松满足用户的日志实时分析、全文检索、结构化数据分析等多种需求,大幅降低大数据时代挖掘数据价值的成本。腾讯在公司内部丰富的场景中大规模使用 ES,同时联合 Elastic 公司在腾讯云上提供内核增强版的 ES 云服务,大规模、丰富多样的的使用场景推动着腾讯对原生 ES 进行持续的高可用、高性能、低成本优化。
一、ES 在腾讯的应用场景
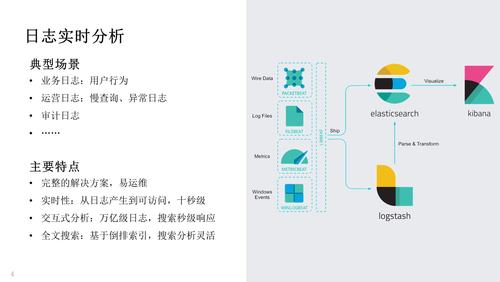
【ES 在腾讯的应用场景】
最初我们使用 ES 于日志实时分析场景,典型日志如下:
运营日志,比如慢日志、异常日志,用来定位业务问题;
业务日志,比如用户的点击、访问日志,可以用来分析用户行为;
审计日志,可以用于安全分析。ES 很完美的解决了日志实时分析的需求,它具有如下特点:
Elastic 生态提供了完整的日志解决方案,任何一个开发、运维同学使用成熟组件,通过简单部署,即可搭建起一个完整的日志实时分析服务。
在 Elastic 生态中,日志从产生到可访问一般在 10s 级。相比于传统大数据解决方案的几十分钟、小时级,时效性非常高。
由于支持倒排索引、列存储等数据结构,ES 提供非常灵活的搜索分析能力。
支持交互式分析,即使在万亿级日志的情况下,ES 搜索响应时间也是秒级。
日志是互联网行业最基础、广泛的数据形式,ES 非常完美的解决了日志实时分析场景,这也是近几年 ES 快速发展的一个重要原因。
第二类使用场景是搜索服务,典型场景包含:商品搜索,类似京东、淘宝、拼多多中的商品搜索;APP 搜索,支持应用商店里的应用搜索;站内搜索,支持论坛、在线文档等搜索功能。我们支持了大量搜索服务,它们主要有以下特点:
高性能:单个服务大达到 10w+ QPS,平响 20ms~,P95 延时小于 100ms。
强相关:搜索体验主要取决于搜索结果是否高度匹配用户意图,需要通过正确率、召回率等指标进行评估。
高可用:搜索场景通常要求 4 个 9 的可用性,支持单机房故障容灾。任何一个电商服务,如淘宝、京东、拼多多,只要故障一个小时就可以上头条。
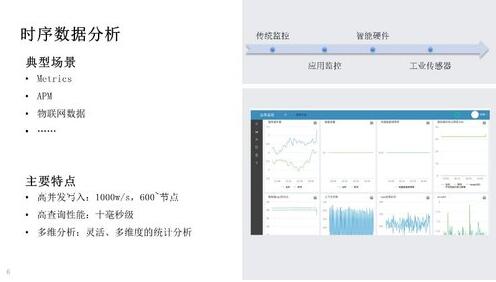
第三类使用场景是时序数据分析,典型的时序数据包含:Metrics,即传统的服务器监控;APM,应用性能监控;物联网数据,智能硬件、工业物联网等产生的传感器数据。这类场景腾讯很早就开始探索,在这方面积累了非常丰富的经验。这类场景具有以下特点:
高并发写入:线上单集群大规模达到 600+节点、1000w/s 的写入吞吐。
高查询性能:要求单条曲线 或者单个时间线的查询延时在 10ms~。
多维分析:要求灵活、多维度的统计分析能力,比如我们在查看监控的时候,可以按照地域、业务模块等灵活的进行统计分析。
二、遇到的挑战
前面我们介绍了 ES 在腾讯内部的广泛应用,在如此大规模、高压力、丰富使用场景的背景下,我们遇到了很多挑战,总体可以划分为两类:搜索类和时序类。

首先,我们一起看看搜索类业务的挑战。以电商搜索、APP 搜索、站内搜索为代表,这类业务非常重视可用性,服务 SLA 达到 4 个 9 以上,需要容忍单机故障、单机房网络故障等;同时要求高性能、低毛刺,例如 20w QPS、平响 20ms、P95 延时 100ms。总之,在搜索类业务场景下,核心挑战点在于高可用、高性能。
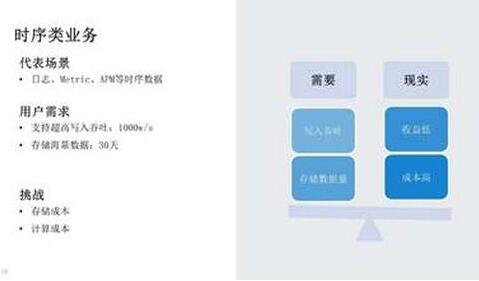
另一类我们称之为时序类业务挑战,包含日志、Metrics、APM 等场景。相比于搜索类业务重点关注高可用、高性能,时序类业务会更注重成本、性能。比如时序场景用户通常要求高写入吞吐,部分场景可达 1000w/s
WPS;在这样写入吞吐下,保留 30 天的数据,通常可达到 PB 级的存储量。而现实是日志、监控等场景的收益相对较低,很可能用户用于线上实际业务的机器数量才是 100 台,而监控、日志等需要 50 台,这对多数用户来说,基本是不可接受的。所以在时序类业务中,主要的挑战在于存储成本、计算成本等方面。
前面我们介绍了在搜索类、时序类业务场景下遇到的高可用、低成本、高性能等挑战,下面针对这些挑战,我们重点分享腾讯在 ES 内核方面的深入实践。
三、ES 优化实践
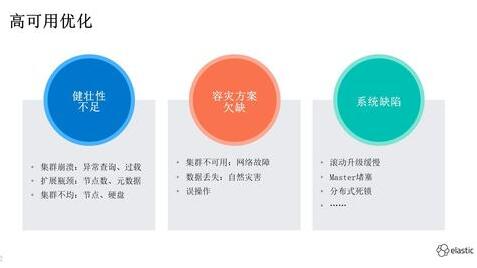
首先,我们来看看高可用优化,我们把高可用划分为三个维度:
系统健壮性:是指 ES 内核自身的健壮性,也是分布式系统面临的共性难题。例如,在异常查询、压力过载下集群的容错能力;在高压力场景下,集群的可扩展性;在集群扩容、节点异常场景下,节点、多硬盘之间的数据均衡能力。
容灾方案:如果通过管控系统建设,保障机房网络故障时快速恢复服务,自然灾害下防止数据丢失,误操作后快速恢复等。
系统缺陷:这在任何系统发展过程中都会持续产生,比如说 Master 节点堵塞、分布式死锁、滚动重启缓慢等。
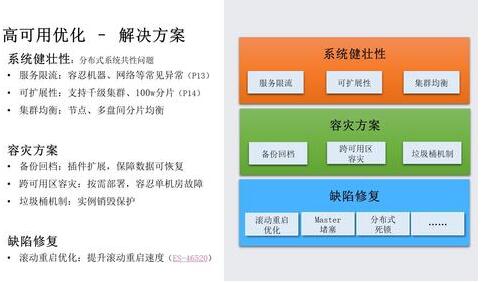
针对上述问题,下面来介绍我们在高可用方面的解决方案:
系统健壮性方面,我们通过服务限流,容忍机器网络故障、异常查询等导致的服务不稳定,后面展开介绍。通过优化集群元数据管控逻辑,提升集群扩展能力一个数量级,支持千级节点集群、百万分片,解决集群可扩展性问题;集群均衡方面,通过优化节点、多硬盘间的分片均衡,保证大规模集群的压力均衡。
容灾方案方面,我们通过扩展 ES 的插件机制支持备份回档,把 ES 的数据备份回档到廉价存储,保证数据的可恢复;支持跨可用区容灾,用户可以按需部署多个可用区,以容忍单机房故障。垃圾桶机制,保证用户在欠费、误操作等场景下,集群可快速恢复。
系统缺陷方面,我们修复了滚动重启、Master 阻塞、分布式死锁等一系列 Bug。其中滚动重启优化,可加速节点重启速度 5+倍,具体可参考 PR ES-46520;Master 堵塞问题,我们在 ES 6.x 版本和官方一起做了优化。
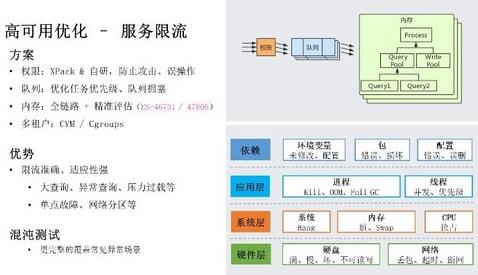
这里我们展开介绍下服务限流部分。我们做了 4 个层级的限流工作:权限层级,我们支持 XPack 和自研权限来防止攻击、误操作;队列层级,通过优化任务执行速度、重复、优先级等问题,解决用户常遇到的 Master 任务队列堆积、任务饿死等问题;内存层级,我们从 ES 6.x 开始,支持在 HTTP 入口、协调节点、数据节点等全链路上进行内存限流,同时使用 JVM 内存、梯度统计等方式精准控制;多租户层级,我们使用 CVM/Cgroups 方案保证多租户间的资源隔离。
这里详细介绍下聚合场景限流问题,用户在使用 ES 进行聚合分析时,经常遇到因聚合分桶过多打爆内存的问题。官方在 ES 6.8 中提供 max_buckets 参数控制聚合的大分桶数,但这个方式局限性非常强。在某些场景下,用户设置 20 万个分桶可以正常工作,但在另一些场景下,可能 10 万个分桶内存就已经打爆,这主要取决于单分桶的大小,用户并不能准确把握该参数设置为多少比较合适。我们在聚合分析的过程中,采用梯度算法进行优化,每分配 1000 个分桶检查一次 JVM 内存,当内存不足时及时中断请求,保证 ES 集群的高可用。具体可参考 PR ES-46751 /47806。
我们当前的限流方案,能够大幅提升在异常查询、压力过载、单节点故障、网络分区等场景下,ES 服务的稳定性问题。但还有少量场景没有覆盖完全,所以我们目前也在引入混沌测试,依赖混沌测试来覆盖更多异常场景。
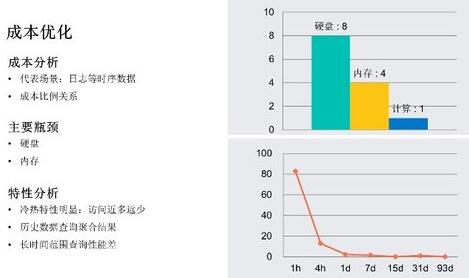
前面我们介绍了高可用解决方案,下面我们来介绍成本方面的优化实践。成本方面的挑战,主要体现在以日志、监控为代表的时序场景对机器资源的消耗,我们对线上典型的日志、时序业务进行分析,总体来看,硬盘、内存、计算资源的成本比例接近 8:4:1,硬盘、内存是主要矛盾,其次是计算成本。
而对时序类场景进行分析,可以发现时序数据有很明显的访问特性。一是冷热特性,时序数据访问具有近多远少的特点,最近 7 天数据的访问量占比可达到 95%以上;历史数据访问较少,且通常都是访问统计类信息。
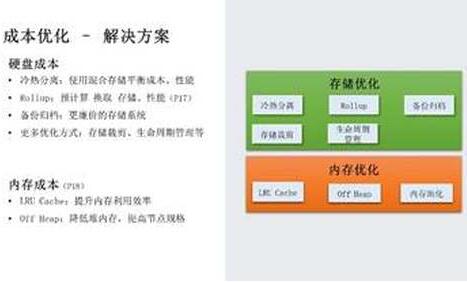
基于这些瓶颈分析和数据访问特性,我们来介绍成本优化的解决方案。
硬盘成本方面,由于数据具有明显的冷热特性,首先我们采用冷热分离架构,使用混合存储的方案来平衡成本、性能;其次,既然对历史数据通常都是访问统计信息,那么以通过预计算来换取存储和性能,后面会展开介绍;如果历史数据完全不使用,也可以备份到更廉价的存储系统;其他一些优化方式包含存储裁剪、生命周期管理等。
内存成本方面,很多用户在使用大存储机型时会发现,存储资源才用了百分之二十,内存已经不足。其实基于时序数据的访问特性,我们可以利用 Cache 进行优化,后面会展开介绍。
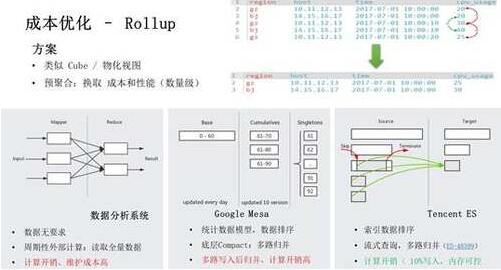
我们展开介绍下 Rollup 部分。官方从 ES 6.x 开始推出 Rollup,实际上腾讯在 5.x 已经开始这部分的实践。Rollup 类似于大数据场景下的 Cube、物化视图,它的核心思想是通过预计算提前生成统计信息,释放掉原始粒度数据,从而降低存储成本、提高查询性能,通常会有数据级的收益。这里举个简单的例子,比如在机器监控场景下,原始粒度的监控数据是 10 秒级的,而一个月之前的监控数据,一般只需要查看小时粒度,这即是一个 Rollup 应用场景。
在大数据领域,传统的方案是依赖外部离线计算系统,周期性的读取全量数据进行计算,这种方式计算开销、维护成本高。谷歌的广告指标系统 Mesa 采用持续生成方案,数据写入时系统给每个 Rollup 产生一份输入数据,并对数据进行排序,底层在 Compact/Merge 过程中通过多路归并完成 Rollup,这种方式的计算、维护成本相对较低。ES 从 6.x 开始支持数据排序,我们通过流式查询进行多路归并生成 Rollup,最终计算开销小于全量数据写入时 CPU 开销的 10%,内存使用小于 10MB。我们已反馈内核优化至开源社区,解决开源 Rollup 的计算、内存瓶颈,具体可参考 PR ES-48399。
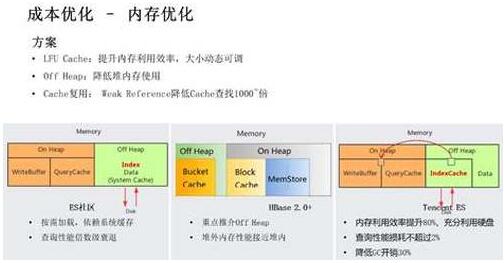
接下来,我们展开介绍内存优化部分。前面提到很多用户在使用大存储机型时,内存优先成为瓶颈、硬盘不能充分利用的问题,主要瓶颈在于索引占用大量内存。但是我们知道时序类场景对历史数据访问很少,部分场景下某些字段基本不使用,所我们可以通过引入 Cache 来提高内存利用效率。
在内存优化方面,业界的方案是什么样的呢?ES 社区从 7.x 后支持索引放于堆外,和 DocValue 一样按需加载。但这种方式不好的地方在于索引和数据的重要性完全不同,一个大查询很容易导致索引被淘汰,后续查询性能倍数级的衰减。Hbase 通过缓存 Cache 缓存索引、数据块,提升热数据访问性能,并且从 HBase 2.0 开始,重点介绍其 Off Heap 技术,重点在于堆外内存的访问性能可接近堆内。我们基于社区经验进行迭代,在 ES 中引入 LFU Cache 以提高内存的利用效率,把 Cache 放置在堆外以降低堆内存压力,同时通过 Weak Reference、减少堆内外拷贝等技术降低损耗。最终效果是内存利用率提升 80%,可以充分利用大存储机型,查询性能损耗不超过 2%,GC 开销降低 30%。
前面我们介绍了可用性、成本优化的解决方案,最后我们来介绍性能方面的优化实践。以日志、监控为代表的时序场景,对写入性能要求非常高,写入并发可达 1000w/s。然而我们发现在带主键写入时,ES 性能衰减 1+倍,部分压测场景下,CPU 无法充分利用。以搜索服务为代表的场景,对查询性的要求非常高,要求 20w QPS, 平响 20ms,而且尽量避免 GC、执行计划不优等造成的查询毛刺。

针对上述问题,我们介绍下腾讯在性能方面的优化实践:
写入方面,针对主键去重场景,通过利用索引进行裁剪,加速主键去重的过程,写入性能提升 45%,具体可参考 PR
Lucene-8980。对于部分压测场景下 CPU 不能充分利用的问题,通过优化 ES 刷新 Translog 时的资源抢占,提升性能提升 20%,具体可参考 PR ES-45765 /47790。我们正在尝试通过向量化执行优化写入性能,通过减少分支跳转、指令 Miss,预期写入性能可提升 1 倍。
查询方面,我们通过优化 Merge 策略,提升查询性能,这部分稍后展开介绍。基于每个 Segment 记录的 min/max 索引,进行查询剪枝,提升查询性能 30%。通过 CBO 策略,避免查询 Cache 操作导致查询耗时 10+倍的毛刺,具体可参考Lucene-9002。此外,我们也在尝试通过一些新硬件来优化性能,比如说英特尔的 AEP、Optane、QAT 等。
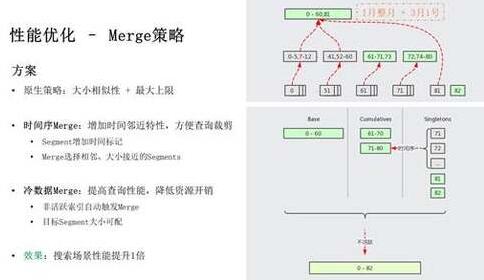
接下来我们展开介绍下 Merge 策略优化部分。ES 原生的 Merge 策略主要关注大小相似性和大上限,大小相似性是指 Merge 时尽量选择大小相似的 Segments 进行 Merge,大上限则考虑尽量把 Segment 拼凑到 5GB。那么有可能出现某个 Segment 中包含了 1 月整月、3 月 1 号的数据,当用户查询 3 月 1 号某小时的数据时,就必须扫描大量无用数据,性能损耗严重。
我们在 ES 中引入了时序 Merge,在选择 Segments 进行 Merge 时,重点考虑时间因素,这样时间相近的 Segments 被 Merge 到一起。当我们查询 3 月 1 号的数据时,只需要扫描个别较小的 Segments 就好,其他的 Segments 可以快速裁剪掉。
另外,ES 官方推荐搜索类用户在写入完成之后,进行一次 Force Merge,用意是把所有 Segments 合并为一个,以提高搜索性能。但这增加了用户的使用成本,且在时序场景下,不利于裁剪,需要扫描全部数据。我们在 ES 中引入了冷数据自动 Merge,对于非活跃的索引,底层 Segments 会自动 Merge 到接近 5GB,降低文件数量的同时,方便时序场景裁剪。对于搜索场景,用户可以调大目标 Segment 的大小,使得所有 Segments 最终 Merge 为一个。我们对 Merge 策略的优化,可以使得搜索场景性能提升 1 倍。
前面介绍完毕我们再 ES 内核方面的优化实践,最后我们来简单分享下我们在开源贡献及未来规划方面的思考。
四、未来规划及开源贡献

近半年我们向开源社区提交了 10+PR,涉及到写入、查询、集群管理等各个模块,部分优化是和官方开发同学一起来完成的,前面介绍过程中,已经给出相应的 PR 链接,方便大家参考。我们在公司内部也组建了开源协同的小组,来共建 Elastic 生态。
总体来说,开源的收益利大于弊,我们把相应收益反馈出来,希望更多同学参与到 Elastic 生态的开源贡献中:首先,开源可以降低分支维护成本,随着自研的功能越来越多,维护独立分支的成本越来越高,主要体现在与开源版本同步、快速引入开源新特性方面;其次,开源可以帮助研发同学更深入的把控内核,了解最新技术动态,因为在开源反馈的过程中,会涉及与官方开发人员持续的交互。此外,开源有利于建立大家在社区的技术影响力,获得开源社区的认可。最后 Elastic 生态的快速发展,有利于业务服务、个人技术的发展,希望大家一起参与进来,助力 Elastic 生态持续、快速的发展。

未来规划方面,这次分享我们重点介绍了腾讯在 ES 内核方面的优化实践,包含高可用、低成本、高性能等方面。此外,我们也提供了一套管控平台,支持线上集群自动化管控、运维,为腾讯云客户提供 ES 服务。但是从线上大量的运营经验分析,我们发现仍然有非常丰富、高价值的方向需要继续跟进,我们会持续继续加强对产品、内核的建设。

长期探索方面,我们结合大数据图谱来介绍。整个大数据领域,按照数据量、延时要求等特点,可以划分为三部分:第一部分是 Data Engineering,包含我们熟悉的批量计算、流式计算;第二部分是 Data Discovery,包含交互式分析、搜索等;第三个部分是 Data Apps,主要用于支撑在线服务。
虽然我们把 ES 放到搜索领域内,但是也有很多用户使用 ES 支持在线搜索、文档服务等;另外,我们了解到有不少成熟的 OLAP 系统,也是基于倒排索引、行列混存等技术栈,所以我们认为 ES 未来往这两个领域发展的可行性非常强,我们未来会在 OLAP 分析和在线服务等方向进行重点探索。




















