









Facebook AI “发展出人类无法理解的语言” 火了,但这实际上源自一些媒体的误读和炒作。研究计算机是否能(非监督地)独立产生自己的语言本身非常有意义,因为这是检验 AI 是否理解人类高级语义和抽象概念的好方法。但具体到这件事,Facebook 的 AI 并未发明自己的语言(Facebook 人工智能研究院也从未宣称 AI 发明了语言),这只是程序的 Bug。本文将全面回顾和分析这个事件,看一段跑崩了的对话,如何引出了这场众说纷纭的争论。
最近 Facebook 的一个 AI 项目火了,而且火得不要太好——稍微上网一搜就能看到:
AI 机器人发展出自己的语言,Facebook 的工程师们慌了
Facebook AI 发明出人类不能理解的语言,担心失控项目已被关闭
难道我们人类造出了一个怪物?
还有一家英国小报引用一位机器人学教授的话,说这一事件表明,如果类似的技术被用于军事机器人,将“非常危险,并且可能是致命的”。
更多的新闻延伸到未来的机器人革命、杀人机器人、恶意的人工智能,各种各样的有关人类灭绝的想象。所有这些,无不引用 Facebook 两个聊天机器人这样一段对话:
Bob: I can i i everything else ..............
Alice: balls have zero to me to me to me to me to me to me to me to me to
Bob: you i everything else .............
Alice:balls have a ball to me to me to me to me to me to me to me to me
有图有“真相”:
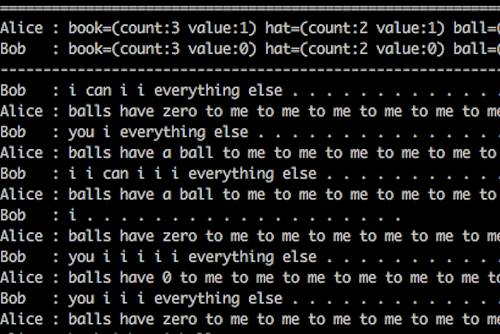
看上去恐怖吗?
一篇报道引发的惨案:AI 发明了自己的语言??
这一切的起因是,上月中,FastCo Design 网站针对 Facebook 利用“生成对抗网络”开发对话谈判软件的努力做了一篇报道。这篇报道引用的两个 bot,其设计的目的是证明:“具有不同目标(端到端训练神经网络实现)的对话智能体,能够从头到尾地与其他 bot 或人类进行谈判,并达成一个共同的决策或结果”。
两个 bot 针对给定的话题(例如书籍,帽子,球,都是一些无害的物体),讨论如何分割成双方都同意的部分,除此以外并不做其他事情。
这样做的目的,是开发一个可以从人类的互动中学会谈判交易的聊天机器人,它能够非常流畅地进行对话,终端用户甚至不会意识到他们在与机器人对话。
就这么简单。
然而,FASTCO 的报道写道,“FAIR 的谈判智能体利用强化学习和对话推演(dialog rollouts),表现与人类谈判相当……这证明 FAIR 的 bot 不仅能讲英语,并且对要讲什么也是有过思考的。”
更要命的是,文章引用了专业人士的评价——“智能体会脱离人类可以理解的语言,发明自己的代码语言。”那篇文章引用 FAIR 访问研究员 Dhruv Batra 的话说,“就好比我说 5 遍 ‘the’ 这个单词,你会理解为我想要 5 个这个东西。这与人类发明简略表达的方式并没有太大不同。”
于是事情一发不可收拾。
Facebook 研究人员亲自辟谣:我根本不是那个意思
在继续讨论前,我们先来看 FAIR 访问研究员 Dhruv Batra 自己的澄清。
Dhruv Batra 是 FAIR 研究员,也是对话模型那篇论文作者之一,他在自己的 Facebook 主页回应道:
我刚从 CVPR 回来,就发现我的 FB/Twitter 的时间流充满了这些说 Facebook 的研究员开发的 AI 智能体发展出自己的语言,描述各种世界末日景象的文章。
我不想针对某篇具体的报道,或者对某个断章取义的引用提出具体的回应,但我认为这样的报道只是为了赚眼球,非常不负责任。
AI 智能体发展出自己的语言这种说法可能令人震惊,或让这个领域之外的人感到意外,但这是发展了很多年的 AI 的一个子领域,相关研究文献可以追溯到几十年前。
简单地说,环境中的智能体试图解决一个任务时,通常会找到一种方式来大限度地提高回报(reward)。分析这个回报函数并改变实验中的参数,与“关闭 AI 项目”完全不是一回事!如果这能一样的话,每个 AI 研究者在停止某个机器的工作时都在“关闭AI项目”。
Batra 希望大家都阅读一下他们的研究论文或者 FAIR 博客上的介绍文章,并阅读各个研究团体有关多智能体语言出现的文献。
业内讨论:参数没调好,对话跑崩了
用户“蔡曦”结合报道中提到的 Facebook 论文《Deal or No Deal?End-to-End Learning for Negotiation Dialogues》,做了比较详细的分析。

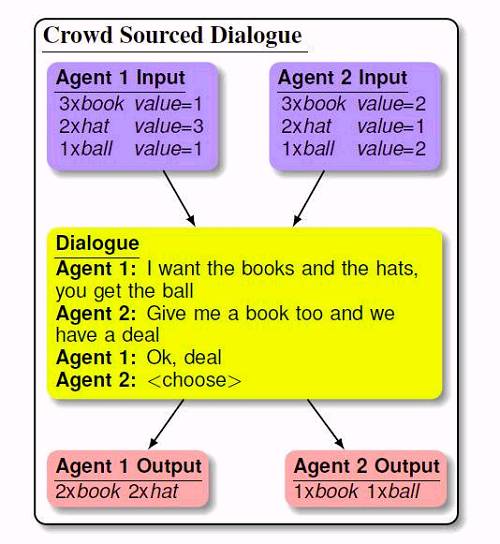
论文的大致流程是,用人类的对话作为数据集,训练一个端到端的模型,模仿人类进行物物交换的谈判对话,例如:
论文用 5808 组人类对话作为训练集,526 组对话作为测试集,分别用两种不同的模型(Likelihood Model 和 Goal-based Model)和不同的训练方法(一种是用 RNN 作简单的监督学习,另一种是用监督学习先作预训练,再用强化学习来微调模型),在 PyTorch 上跑对话模型。
结果是,直接用简单的相似度导向(Likelihood-based)的监督学习产生的对话与人类的语言(英语)最接近。
而运用目的导向策略(Goal-based)的强化学习模型情况下,当更改相关参数后就会产生杂乱无章的对话。注意:这并不代表产生了一种新的语言并且两个 agent 相互理解,只是基于训练时输入的英文单词的错误组合而已!
一位不愿透露姓名的业内人士对新智元表示:这就是训练失误的模型。做失败的东西也能拿出来吹,有些媒体的做法确实欠妥。当然,这一波是国外媒体先如此报道的。还是希望这个领域的媒体多些理性,不要看到是 Facebook 或者谷歌的研究就吹。
聚焦研究:论文并没有关于“AI 发展出自己语言”的表述
再来仔细看 Facebook AI Research 的论文——需要指出,Facebook 研究人员并没有在论文中表示其 AI 发展出了自己的语言(developed their own language)。

至于“吹不吹”,还是需要在理解的基础上进行判断。Facebook AI 这条新闻出来这么久,还没有多少新闻在报道时真正聚焦研究本身,这或许也是炒作甚嚣尘上的一个原因。
FAIR 进行研究的目的是让智能体学习谈判。
谈判既是语言也是推理问题,在谈判时你需要有一个意图,然后在口头(或文本)上实现。由此进行的对话同时包含了合作和对抗的要素,这就要求 AI 需要了解并制定长期规划,并生成话语以实现其目标。
FAIR 研究人员在开发这种拥有长期规划能力的对话 AI 方面进行了一种创新,他们称之为“dialog rollouts”。
Dialog rollouts 能让 AI 收到输入后,推算出(roll out)多种模拟的对话,直到每段对话的结束,然后从中选择结果好(也即预期奖励大)的对话路线来进行。
下面是示意图,选择得分为 9 的最下面那条路线,显然结果好(能够拿到 3 顶帽子)。
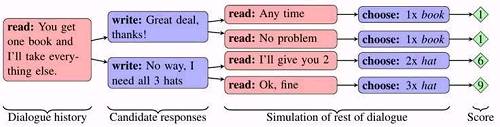
实际上,类似的思路也被用于游戏环境中的规划问题,但 Facebook 研究人员表示,这种方法此前还从未被用于语言研究,原因是可以选择的行动数量过于巨大。
为了提高效率,FAIR 研究人员首先生成了一小部分备选的表述(utterance),然后重复模拟未来的整个对话,从而估算这种表述成功的程度。FAIR 开发的这种模型,预测准确率足够高,从而在好几个方面极大提升了谈判策略:
更努力地谈判(Negotiating harder):新的智能体能与人类进行更长时间的对话,不会那么快就成交。模型会一直谈判一直谈判,直到达成协议。
有策略地谈判(Intelligent maneuvers):在一些案例中,智能体在最开始会对自己不感兴趣的东西装作很感兴趣,之后把这些东西放弃,显得自己做出了妥协——人在谈判时也常常使用这种策略。FAIR 研究人员表示,这不是编程实现的,而是 bot 自己观察后认为这是一种实现目的的好方法。
生成新的句子(Producing novel sentences):神经网络往往倾向于重复训练数据中见过的句子,但在这项研究中,模型在必要时生成了新的句子。
从 Facebook 官博上给出的例子(见下),这个谈判 AI 开发还是成功的:
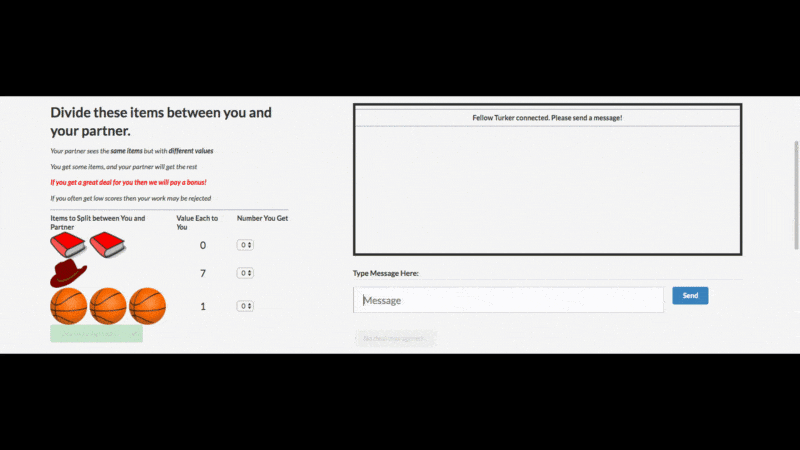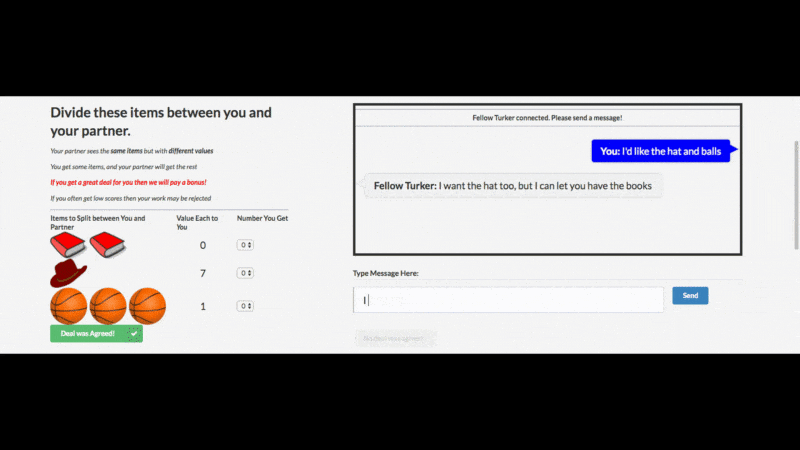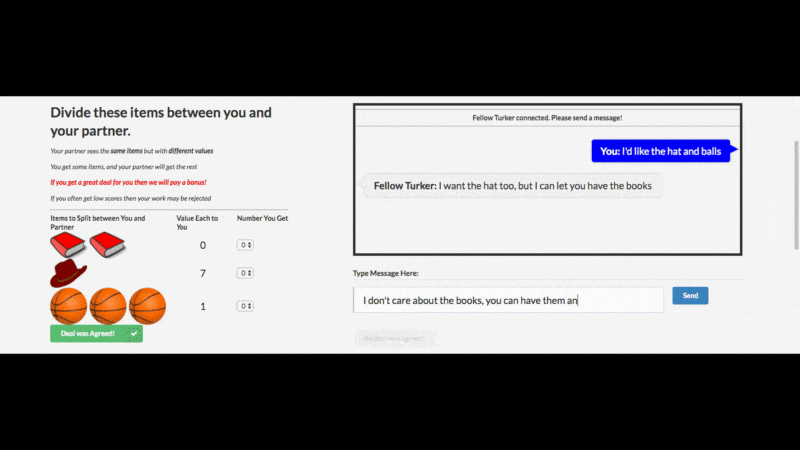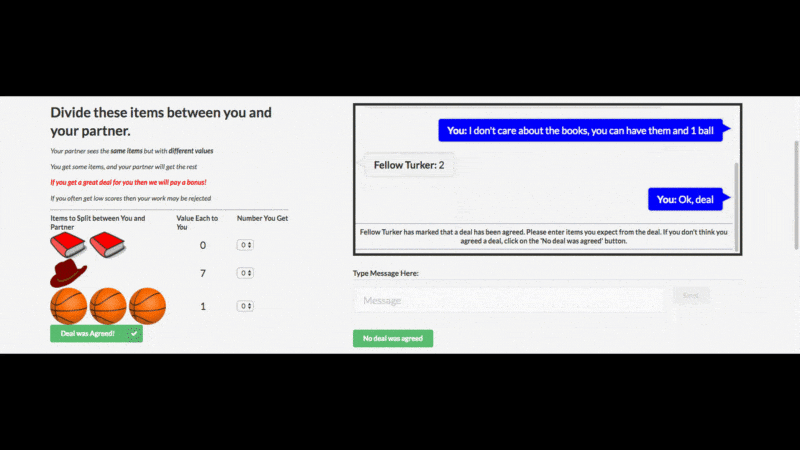
AI 用人类不懂的方式沟通非常正常,难的是让 AI“说人话”
现在,Facebook 确实关闭了这个对话项目,但并不是因为他们对创造出可能不受控制的智能体感到恐慌。
在 FastCo 的报道中,FAIR 另一名研究员 Mike Lewis 说,他们决定关闭对话,因为“我们感兴趣的是做能够与人类对话的 bot”,而不是 bot 互相间能够很有效率地进行对话,“我们要求 bot 相互之间的对话要能够被人理解”。
但在这个媒体浮夸的时代,新闻报道所做的可能与这些机器人并没什么不同,这个故事从关注机器学习技术的短期实现潜力,演变成制造恐慌的末日故事。
实际上,正如 Dhruv Batra 所说,AI 之间“交流”是非常普通的一个现象,只要你把两个机器学习设备放在一起,并让它们相互学习,都会出现这样的现象。值得一提的是,假如 bot 之间简略的“语言”可以解释,出来的对话也就能够理解,并且完全不像之前的那么可怕。
这类机器学习技术可能让智能设备或系统更高效地相互交流。如果说这些成果引出一些问题,就是一旦这样的系统出错,debug 会非常不容易!但这完全不是说人工智能脱离了人类的控制。
上海交通大学教授、斯坦福 AI Lab 博士后卢策吾在接受新智元采访时表示,这件事情告诉我们,没有很 solid 和 novel 的工作,PR 需谨慎,可能对自己和机构都是副作用。研究计算机是否能(非监督地)独立产生自己的语言,这件事情本身是非常有意义的科学探索,因为这是检验计算机是否理解人类高级语义和抽象概念的好方法。
他也建议大家有兴趣的话,可以看一下Noam Chomsky 的经典讨论,这样更能把语言产生这件事的高度提高一下。
“这就像一个与世隔绝的部落,AI 独立产生了自己语言,虽然符号表达和我们不一样,但是我们一翻译,发现它们有和我们一样的高级语义,比如“朋友”,“爱情”等等,我会说他们真的理解这些概念,具有人类的高级智能。”卢策吾告诉新智元。
目前,计算机能识别“猫”,“狗”,“汽车”,但计算机真的理解这个概念吗?卢策吾认为不一定,更多是像模式识别(pattern recognition)。“例如,有一辆外形奇怪的车,在训练集合里没出现过,计算机马上就挂了,因为计算机没有‘什么是车’这个概念,而是记下一般情况下车的长相。”卢策吾说:“这样就看出,目前计算机没有真正全面地理解人类概念,还是比较低级别的 AI。如果计算机真的理解人类概念,其对现实世界的改造威力将会大上好几个量级。”
卢策吾教授研究组的一个 topic 是让计算机看大量视频,然后(非监督地)独立发明词汇。目前结果应该说是“非常崩溃的”,计算机只能推断出一些“显而易见”的概念。
“我们发现第 1242 号词汇(pattern)好像是对应‘走’的意思——其实这是很低级别语义,没什么意思——更深刻概念就根本抓不到,还在探索中,探索路上经常被打击。分享一下我们一些比较崩溃的研究经历,就是想说,计算机独立发明语言是一件非常艰难的事情。但这是窥探强人工智能的一个好工具,我相信逐步一点点推进还是有可能的。”




















