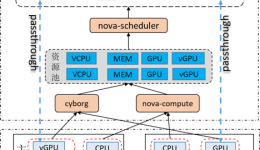
如果你以前曾在云平台上工作过,你一定熟悉这些系统的分布式和解耦性质。解耦的分布式系统依赖于微服务来执行特定的任务,每个微服务都会暴露自己的REST(表示状态转移)API。这些微服务通常以诸如RabbitMQ或QPID等消息中间件的形式通过轻量级消息层相互通信。
这正是OpenStack的工作原理。每个主要的OpenStack组件(Keystone、Glance、Cinder、Neutron、Nova等)公开REST端点,组件和子组件通过消息中间件(如RabbitMQ)进行通信。这种方法的优点首先是允许将故障分配给特定组件,其次是云基础设施运营商可以以水平方式扩展所有服务,并智能分配负载。
然而,这种分布式解耦系统虽然非常有利,但也带来了固有的挑战——如何正确监控OpenStack服务,更具体地说,如何识别可能的单点故障。
下面的内容针对OpenStack服务监控的具体情况所面临的真实挑战,以及每个难题可能的解决方案。
挑战一:系统不是一个整体
OpenStack的非整体性和解耦性通常被强调为其主要优点。这当然是一个重要的优势。然而,这显然会使任何监控整体服务状态的尝试变得复杂。在每个组件执行一个特定任务的分布式系统中,每个组件进一步分布到多个子组件中,因此,不难理解当特定一部分软件发生故障时,确定对服务的影响是多么困难。
克服这个困难的第一步是了解云。你需要确定所有主要组件之间的关系,然后确定每个独立的特定服务之间的关系,它们的故障可能影响整体服务。简单地说,你需要知道云中所有组件之间的关系。
考虑到这一点,你不仅需要监视每个单独组件的状态(正在运行或故障停止),还要确定其他服务如何受到故障的影响。
例如,如果Keystone死机,没有人能够获取服务目录或登录任何服务,但这通常不会影响虚拟机或其他已建立的云服务(对象存储、块存储、负载均衡器等),除非重新启动服务且Keystone仍然宕机。然而,如果Apache失效,通过Apache工作的Keystone和其他类似的API服务可能会受到影响。
因此,监控平台或解决方案不仅必须能够评估各个服务的状态,而且还要能够在服务故障之间进行关联,以便检查对整个系统的真正影响,并相应地发送警报或通知。
挑战二:OpenStack不仅仅是OpenStack
基于OpenStack的云不仅是分布式和解耦式系统,也是一种可在操作系统和其他在云基础设施中或与之相关的设备中创建资源的编排解决方案。这些资源包括虚拟机(Xen、KVM或其他管理程序软件组件)、持久卷(NFS存储服务器、Ceph群集、基于SAN的LVM卷或其他存储后端)、网络实体(端口,网桥,网络,路由器,负载平衡器,防火墙,VPN等)和临时磁盘(驻留在操作系统目录中的Qcow2文件)以及许多其他小型系统。
因此,监测解决方案必须考虑到这些基础组件。虽然这些资源可能不太复杂,并且不太容易出现故障,但是当它们停止运行时,主要OpenStack服务中的日志可能会掩盖真实的原因。它们仅在受到影响的OpenStack服务中显示结果,而不显示设备或失效的操作系统软件的实际根本原因。
例如,如果libvirt失效,组件Nova将无法部署虚拟实例。 Nova-compute作为服务将被启动并运行,但在部署阶段实例将失败(实例状态:错误)。为了检测这一点,你需要在nova-compute日志之外还监控libvirt(服务状态、指标及日志)。
因此,有必要检查底层软件和主要组件之间的关系,以及监控最终的链接,并考虑所有最终服务的一致性测试。你需要监控所有内容:存储、网络、hypervision层、每个单独的组件以及之间的关系。
挑战三:跳出固有思维模式
Cacti、Nagios和Zabbix是OpenSource监控解决方案的好例子。这些解决方案定义了一组非常具体的度量标准,用于识别操作系统上的可能问题,但是它们不提供确定更复杂的故障情况或甚至服务状态所需的专门的指标。
这是你需要有创造性的地方。你可以实施专门的指标和测试,以定义服务是否正常、降级或完全失败。
像OpenStack这样的分布式系统,其中每个核心服务都暴露了一个REST API,并且连接到基于TCP的消息服务,容易受到网络瓶颈、连接池耗尽和其他相关问题的影响。许多相关服务连接到基于SQL的数据库,这可能会耗尽其大连接池,意味着需要在监控解决方案中实施正确的连接状态监控指标(建立、散布等待、关闭等),以检测可能的、影响API的连接相关问题。此外,可以构建cli测试来检查端点状态并测量其响应时间,这可以被转换成实际显示服务真实状态的指标。
上述每一个监控解决方案和大多数其他商业或OpenSource解决方案可以通过自行设计专门指标来进行扩展。
命令“time OpenStack catalogue list”可以测量Keystone API响应时间,评估结果,并在结果不符合预期时产生人工故障状态。此外,你可以使用简单的操作系统工具,如“netstat”或“ss”,来监控API端点的不同连接状态,并了解服务中可能出现的问题。OpenStack云依赖关系的关键部分(例如消息代理和数据库服务)也可以这样做。请注意,消息中间件失败基本上将“杀死”OpenStack云。
关键是不要偷懒!不要只用默认的指标,而是应该用与自己服务相关的指标。
挑战四:人为因素
人为因素关乎一切。俗话说,埋怨工具的工匠不是一个好工匠。
没有经过测试的情景响应程序,单一故障不仅本身是一个问题,还将带来造更多的问题。在你的监控解决方案中,云基础设施的任何事故及其相关警报中都应该有明确的记录,以清楚的步骤来解释如何检测、遏制和解决问题。
人为因素必须考虑,即使你有一个可以关联事件和建议适当的解决方案来检测事故的、聪明的系统(一个有一定程度人工智能的系统)。请务必记住,如果系统不正确或不完整,那么输出也将不准确或不完整。
总结一下,OpenStack监控不一定很困难,最重要的是要彻底。每个单独的服务以及与其他服务的互动都需要仔细监控。特殊指标甚至可以自己实现。通过一些TLC,你可以轻松地成功监控你的OpenStack。